Sí, de drogas de las que mantienen despierto al lumpenazgo. Porque he encontrado (aquí) un conjunto datos muy interesante sobre la valoración que una serie de personas, unas 900, da a una serie de drogas más o menos legales que se llaman —me acabo de enterar— nootrópicos.
El gráfico

extraído de la página enlazada más arriba resume parte de los resultados. No obstante, es sabido entre los que se dedican a los sistemas de recomendación que hay usuarios que tienden a valorar sistemáticamente por encima de la media y otros, por debajo. En los manuales de la cosa suelen recogerse mecanismos más o menos sofisticados para mitigar ese efecto y normalizar las valoraciones entre usuarios. Generalmente, solo exigen matemáticas de bachillerato. Y son meras aproximaciones que no tienen en cuenta circunstancias tales como que puede que un usuario da valoraciones bajas solo porque evalúa productos malos, etc.
Aquí y en sus enlaces se habla de una manera más sofisticada de corregir ese sesgo: modelos mixtos. Tales como
library(xlsx)
library(reshape2)
library(lme4)
library(plyr)
library(lattice)
download.file("/uploads/recomendador_drogas.xlsx",
destfile = "recomendador_drogas.xlsx")
raw <- read.xlsx("recomendador_drogas.xlsx", 1)
# selección de las columnas de interés
dat <- raw[, c(8:40, 42, 48, 53)]
# limpieza de nombres
colnames(dat)[grep("Semax", colnames(dat))] <- "Semax"
colnames(dat)[grep("Selank", colnames(dat))] <- "Selank"
colnames(dat)[grep("Alpha.Brain", colnames(dat))] <- "Alpha.Brain"
colnames(dat)[grep("Epicor", colnames(dat))] <- "Epicor"
colnames(dat)[grep("LSD.Microdosing", colnames(dat))] <- "LSD.Microdosing"
colnames(dat)[grep("Adderall", colnames(dat))] <- "Adderall"
colnames(dat)[grep("Phenibut", colnames(dat))] <- "Phenibut"
# preparación de los datos
dat$id <- 1:nrow(dat)
dat <- melt(dat, id.vars = "id")
colnames(dat) <- c("usuario", "droga", "nota")
dat <- na.omit(dat)
dat$usuario <- as.character(dat$usuario)
# tabla que replica la publicada más arriba
ranking <- ddply(dat, .(droga), summarize, nota = mean(nota))
ranking <- ranking[order(-ranking$nota),]
# modelo mixto: incluye efectos aleatorios por usuario y por droga
modelo <- lmer(nota ~ 1 + (1|usuario) + (1|droga), data = dat)
dotplot(ranef(modelo, condVar = TRUE))que produce, entre otros, el gráfico
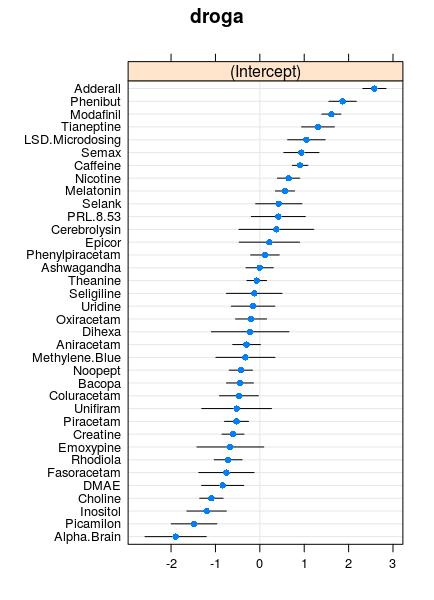
Esencialmente, el orden se mantiene (salvo alguna excepción). Pero ahora se aprecian los intervalos de confianza (debidos a la desigual popularidad de los ítems).