En el primer número de la novísima revista Spanish Journal of Statistics aparece un artículo con un título tentador: Recovering income distributions from aggregated data via micro-simulations.
Es decir, un artículo que nos puede permitir, por ejemplo, muestrear lo que la AEAT llama rendimientos a partir de lo que publica (aquí):

Uno de los métodos de los que sostienen el ignominioso a mí me funciona está basado en el modelo
lm(log(x) ~ poly(p, 3))
donde x es el extremo superior del tramo y p es la proporción acumulada de sujetos.
Con los datos de la AEAT del 2015, quedaría algo así como:
datos <- structure(
list(
hasta = c(1.5, 6, 12, 21, 30, 60, 150, 601, 1000),
contribuyentes = c(0.305, 58.911, 1202.863, 4181.433, 3022.829,
3183.805, 605.617, 74.797, 7.244)),
class = "data.frame",
row.names = 4:12)
datos$prop <- cumsum(datos$contribuyentes) / sum(datos$contribuyentes)
tmp <- datos[-nrow(datos),]
modelo <- lm(log(hasta) ~ poly(prop, 3), data = tmp)
muestra <- exp(predict(modelo, data.frame(prop = runif(10000))))
hist(muestra, breaks = 40)que da algo así como
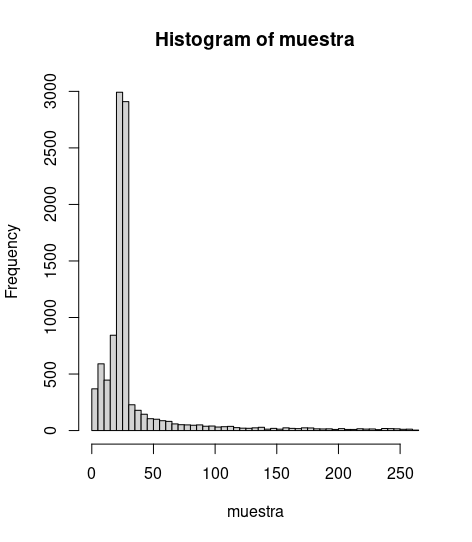
Comparar los cuantiles de la nueva distribución con los originales es ejercicio que queda propuesto al lector.
Addenda: Véase esta entrada anterior.