Me he entretenido estos días en crear un modelo que represente la siguiente hipótesis de trabajo:
Los encuestadores electorales combinan tres fuentes de información: sus propios datos, el consenso de los restantes encuestadores y la voz de su amo, es decir, el interés de quien paga la encuesta.
Es un modelo en el que se introduce (y se mide) el sesgo que introduce cada casa en los resultados. De momento (¡no fiarse!, léase lo que viene después) he obtenido cosas como estas (para el PP):
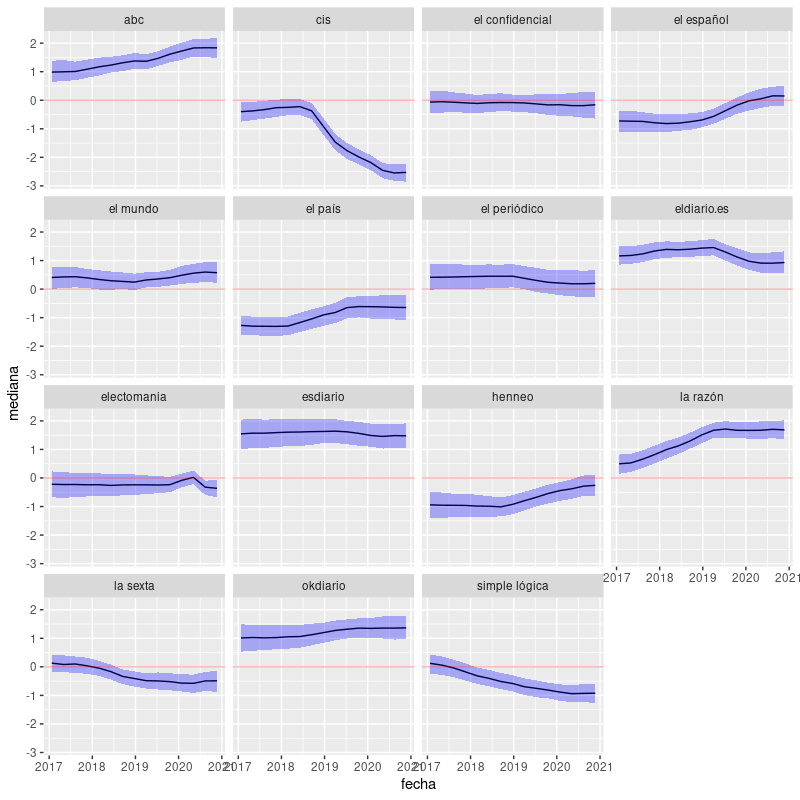
(El gráfico anterior muestra la evolución del sesgo aparente en las propensiones de voto al PP de los medios que más encuestas electorales han publicado en los últimos tiempos acompañado de su correspondiente intervalo de credibilidad del 50%.)
En realidad, me lo he tomado como un pequeño ejercicio de procesos gausianos en stan. Cuando esté más seguro de que la cosa no contiene pufos vegonzantes, lo describiré y lo subiré a GitHub.
Los resultados anteriores han de tomarse con una sustancial dosis de escepticismo porque:
- He visto que la fuente de mis datos de resultados de encuestas tiene un pufo, en particular, para ciertos resultados del CIS. He escrito a los responsables por ver si lo enderezan. Pero ya no me fío: me los imagino con un Excel cargado por el diablo. Tendré que buscar otra (¿Wikipedia? ¿esto?).
- El sistema tiene un sesgo debido a todos esos encuestadores picados de un insecto estajanovista que no paran de producir resultados y que, bajo el actual modelo, sesgan el consenso hacia su buen parecer. Tengo que ve la manera de quitarles peso.
En fin, que es posible que siga publicando cosas al respecto y que tal vez acabe publicando ese portal hiperpunk que planeo desde hace siglos de predicciones electorales especializado en predecir las predicciones de los predictores. Solo para echarme unas risas.