iris1 Tablas (dataframes)
Muy frecuentemente, los datos se disponen en tablas: las hojas de cálculo, las bases de datos, los ficheros csv, etc. contienen, esencialmente, tablas. Además, casi todos los métodos estadísticos (p.e., la regresión lineal) operan sobre información organizada en tablas. Como consecuencia, gran parte del día a día del trabajo con R consiste en manipular tablas de datos para darles el formato necesario para acabar analizándolos estadística o gráficamente.
Las hojas de cálculo son herramientas que prácticamente todos hemos usado para manipular tablas de datos. El objetivo de esta primera parte del libro es aprender a realizar operaciones habituales y bien conocidas por los usuarios de Excel sobre tablas de datos en R.
1.1 Inspección de una tabla
Nuestra primera tarea consistirá en inspeccionar los contenidos de una tabla. Esta es, de hecho, la primera tarea que uno realiza en la práctica cuando recibe un conjunto nuevo de datos: averiguar cuántas filas y columnas tiene, de qué tipo (numérico o no) son sus columnas, etc.
Para practicar y como ejemplo, usaremos una tabla que viene de serie con R, iris1. Tiene 150 filas que corresponden a otras tantas iris (una especie de flor) y sus columnas contienen cuatro características métricas de cada ejemplar: la longitud y la anchura de sus pétalos y sépalos; y la subespecie: setosa, versicolor o virgínica, a la que pertenece. De momento y hasta que aprendamos cómo importar datos de fuentes externas, utilizaremos este y otros conjuntos de datos de ejemplo que incluye R.
Para inspeccionar una tabla utilizaremos una serie de funciones básicas que se usan muy frecuentemente en R.
Escribir en la consola de R2
es lo mismo que ejecutar
print(iris)y muestra la tabla en la consola. Cosa que no es particularmente útil si la tabla tiene muchas filas.
Este comportamiento no es exclusivo de las tablas. Aplica también a otros tipos de datos que veremos más adelante: ejecutar el nombre de un objeto imprime (muestra) directamente en la consola una representación textual del mismo.
Otras funciones útiles para inspeccionar tablas (y, como veremos más adelante, no solo tablas) son
plot(iris) # la representa gráficamente
summary(iris) # resumen estadístico de las columnas
str(iris) # "representación textual" del objetoEjercicio 1.1 Trata de interpretar el gráfico generado con plot(iris). ¿Qué nos dice, p.e., de la relación entre la anchura y la longitud de los pétalos?
Ejercicio 1.2 Trata de intepretar la salida del resto de las anteriores líneas de código. ¿Qué nos dicen del conjunto de datos?
Es impráctico mostrar tablas enteras en la consola, sobre todo cuando son grandes. Para mostrar solo parte de ellas,
head(iris) # primeras seis filas
tail(iris) # últimas seis filasEn R, la ayuda de una función (summary en el ejemplo siguiente), se consulta así3:
?summarySi usas RStudio, el texto de la ayuda correspondiente a esa función aparecerá en la pestaña correspondiente del panel inferior derecho.
Ejercicio 1.3 Consulta la ayuda de la función head y averigua cómo mostrar las diez primeras filas de iris en lugar de las seis que aparecen por defecto.
La ayuda de una función en R siempre tiene la misma estructura:
- una breve descripción de la función,
- una descripción de los argumentos que admite,
- una sección que detalla el funcionamiento de la función y de los distintos argumentos y
- una sección final de ejemplos.
Habitualmente, los ejemplos suelen más instructivos que el resto: con un poco de suerte, el autor de la página de ayuda ha incluido uno que, con pequeños cambios, te puede servir.
Además de lo anterior, para inspeccionar una tabla es fundamental conocer su tamaño
dim(iris) # filas x columnas[1] 150 5nrow(iris) # número de filas[1] 150ncol(iris) # número de columnas[1] 5y el nombre de sus columnas
colnames(iris)[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species" Ejercicio 1.4 Consulta el tamaño, número de filas y el número y nombre de las columnas del conjunto de datos airquality; muestra también las primeras 13 filas de esa tabla.
Ejercicio 1.5 Examina el conjunto de datos attenu. Consulta su ayuda (?attenu) para averiguar qué tipo de información contiene. Finalmente, usa summary para ver si contiene algún nulo en alguna columna.
Ejercicio 1.6 Haz una lista con todas las funciones que aparecen nombradas en esta sección y trata de recordar lo que hace cada una de ellas.
1.2 Selección de filas y columnas
Igual que ocurre con una hoja de cálculo, frecuentemente queremos trabajar con un subconjunto de la tabla, i.e., con una selección de filas y/o columnas. Para este tipo de selecciones se usa el corchete:
iris[1:10,] # diez primeras filas
iris[, 3:4] # columnas 3 y 4
iris[1:10, 3:4]Cuando se opera con tablas, los corchetes siempre4 tienen dos partes separadas por una coma:
- la que la precede se refiere a las filas
- la que la sigue, a las columnas.
No es necesario conocer índice de una determinada columna para seleccionarla: los corchetes admiten también el nombres de columnas:
iris[, "Species"]Es tan habitual extraer y operar sobre columnas individuales de una tabla que R proporciona una manera más breve de hacerlo:
iris$SpeciesDe hecho, se prefiere habitualmente (porque es más rápido y más legible) iris$Species a iris[, "Species"].
R está diseñado fundamentalmente para ser usado interactivamente, es decir, para que el usuario utilice la consola para ensayar, probar distintas alternativas, etc. Por eso R está lleno de atajos pensados para abreviar el trabajo, dispone de operadores flexibles como los corchetes, etc. Eso lo diferencia de otros lenguajes, frecuentemente mucho más rígidos, que están orientados a crear programas más o menos complejos.
El corchete también permite seleccionar filas mediante condiciones lógicas:
iris[iris$Species == "setosa",]Ejercicio 1.7 Selecciona las filas de iris cuya longitud del pétalo sea mayor que 4.
Ejercicio 1.8 Selecciona las filas donde cyl sea menor que 6 y gear igual a 4 en mtcars. Nota: el operador AND en R es &.
La selección de filas mediante condiciones lógicas es muy útil y será muy necesaria posteriormente cuando queramos eliminar sujetos con edades negativas, detectar los pacientes con niveles de glucemia por encima de un determinado umbral, etc.
Los ejemplos anteriores dan cuenta de la versatilidad de []. Dentro de él pueden indicarse:
- coordenadas (o rangos de coordenadas) de filas y columnas
- nombres de columnas
- condiciones lógicas para seleccionar filas que cumplan un criterio determinado
Más adelante, cuando tratemos los vectores5, veremos cómo:
- seleccionar no solo rangos de columnas (p.e.,
1:4), sino columnas determinadas (p.e., la 1, 4 y 7) - seleccionar varias columnas por nombre
- construir condiciones lógicas no triviales
1.3 Creación y eliminación de tablas y columnas
Es posible crear otras tablas a partir de una dada mediante el operador <-, que sirve para asignar:
mi.iris <- iris # mi.iris es una copia de iris
head(mi.iris)Los nombres de objetos siguen las reglas habituales en otros lenguajes de programación: son secuencias de letras y números (aunque no pueden comenzar por un número) y se admiten los separadores _ y .: tanto mi.iris como mi_iris son nombres válidos. Hay quienes prefieren usar camel case, como miIris. Es cuestión de estilo; y, en cuestiones de estilo, todo es discutible salvo la consistencia.
iris, que viene de serie con R, no es un objeto visible. Sin embargo, los que crees tú, sí:
ls() # lista de objetos en memoria
rm(mi.iris) # borra el objeto mi.iris
ls()Además de con la función ls, los objetos que crees aparecerán listados en el panel correspondiente, el superior derecho de RStudio (si es que lo utilizas).
Añadir una columna a una tabla es como crear una nueva variable dentro de ella6. Una manera de eliminarlas es asignarle el valor NULL.
mi.iris <- iris
mi.iris$Petal.Area <- mi.iris$Petal.Length * mi.iris$Petal.Width
mi.iris$Petal.Area <- NULLTen en cuenta que
- agregar una columna que existe la reemplaza,
- agregar una columna que no existe la crea y
- asignar
NULLa una columna existente la elimina.
Ejercicio 1.9 Crea una copia del conjunto de datos airquality. Comprueba con ls que está efectivamente creado y luego añádele una columna nueva llamada temperatura que contenga una copia de Temp. Comprueba que efectivamente está allí y luego, elimínala. Finalmente, borra la tabla.
Ejercicio 1.10 Usando el conjunto de datos CO2, selecciona los valores en los que el tratamiento sea chilled, y el valor de uptake, mayor que 15; devuelve únicamente las 10 primeras filas.
1.4 Ordenación
La reordenación de las filas de una tabla es fundamental para analizar su contenido y, frecuentemente, para detectar problemas en los datos. Por ejemplo, al ordenar los sujetos por edad y echar un vistazo a las primeras filas podemos identificar aquellos que, por error, tienen asociadas edades negativas.
R no dispone de ninguna función de serie para ordenar por una columna (o varias)7. En R, ordenar es seleccionar ordenadamente:
mi.iris <- iris[order(iris$Petal.Length),]La función order aplicada a un vector devuelve otro vector de la misma longitud que tiene el valor 1 en el primer elemento del vector, 2 en el segundo, etc. Es decir, en el ejemplo anterior, mi.iris tiene como primera fila aquella que corresponde al valor más pequeño de iris$Petal.Length, etc.
Ejercicio 1.11 Verifica que mi.iris <- iris[order(-iris$Petal.Length),] ordena decrecientemente.
Ejercicio 1.12 Crea una versión de iris ordenando por especie y dentro de cada especie, por Petal.Length. Ten en cuenta que en R se puede ordenar por dos o más columnas porque order admite dos o más argumentos (véase ?order). Por ejemplo, iris[order(iris$Petal.Length, iris$Sepal.Length),] deshace los empates en Petal.Length de acuerdo con Sepal.Length.
Ejercicio 1.13 Encuentra el día más frío de los que contiene airquality.
Ejercicio 1.14 Usando el mismo conjunto de datos, encuentra el día más caluroso del mes de junio.
1.5 Lectura de datos externos
Por supuesto, no nos vamos a limitar a trabajar con datos de ejemplo provistos por R: queremos utilizar también nuestras propias tablas. En R hay decenas de maneras de importar datos tabulares desde distintas fuentes (Excel, bases de datos, SPSS, etc.) pero la más habitual consiste en leer ficheros de texto con la función read.table.
Existen muchas variantes de ficheros de texto: csv, ficheros separados con tabulador, con y sin encabezamientos, con distintos códigos para representar los nulos, etc. La función read.table es muy flexible y tiene muchos parámetros, casi demasiados, para adaptarse a la mayor parte de ellos8.
Antes de comenzar a utilizarla, sin embargo, es necesaria una digresión acerca de directorios y directorios de trabajo. El directorio de trabajo es aquel en el que R busca y escribe ficheros por defecto. Las funciones getwd y setwd permiten, respectivamente, averiguar cuál es y cambiarlo si procede. De todos modos, la mejor manera de especificar el directorio de trabajo en RStudio es usando los menús: Files > More > Set as working directory.
getwd()
setwd("..") # "sube" al directorio padre del actual
setwd("mi_proyecto/src") # ruta relativa
setwd("c:/users/yo/proyecto") # ruta absoluta en Windows
setwd("/home/yo/proyecto") # ruta absoluta en Linux y otros
dir() # contenidos del directorio "de trabajo"Una llamada típica a read.table para leer un fichero es así:
datos <- read.table("data_dir/mi_fichero.csv", sep = "\t", header = TRUE)Examinénmosla:
datoses el nombre de la tabla que recibirá la información leída porread.table; de no hacerse la asignación, R se limitará a imprimirlos en la consola."data_dir/mi_fichero.csv"(¡entrecomillado!) es la ruta del fichero de interés. Se trata de una ruta relativa al directorio de trabajo, que se supone que contiene el subdirectoriodata_diry, dentro de él, el ficheromi_fichero.csv.sep = "\t"indica que los campos del fichero están separados por tabuladores (sí, el tabulador es\t). Muchos ficheros tienen campos separados por, además del tabulador, caracteres tales como,,;,|u otros. Es necesario indicárselo a R y la manera de averiguar qué separador usa un fichero, si es que no se sabe, es abriéndolo previamente con un editor de texto decente9.header = TRUEindica que la primera fila del fichero contiene los nombres de las columnas. Si olvidas especificarlo y la primera fila del fichero contiene efectivamente el nombre de las columnas, R interpretará estas, erróneamente, como datos.
Con una expresión similar a esa, tal vez cambiando el separador, se leen la mayoría de los ficheros de texto habituales. Otras opciones de las muchas que tiene read.table que pueden ser útiles en determinadas ocasiones son:
dec, para indicar el separador de decimales. Por defecto es., pero en ocasiones hay que cambiarlo adec = ","para que interprete correctamente, p.e., el antiguo estándar español (p.e.,67,56en lugar de67.56).quote, que indica qué caracter se usa para acotar campos de texto. En algunas ocasiones aparecen campos de texto que contienen apóstrofes (p.e., calle O’Donnell) y la carga de datos puede fracasar de no indicarsequote = "". Esta expresión desactiva el papel especial de acotación de campos de texto que por defecto tienen las comillas.
Los siguientes ejercicios (y muchos más a lo largo de libro) hacen referencia a conjuntos de datos disponibles en https://bit.ly/2qS7DvO. Descarga ese fichero y descomprímelo en alguna carpeta.
Ejercicio 1.15 Lee el fichero paro.csv usando la función read.table. Comprueba que está correctamente importado usando head, tail, nrow, summary, etc. Para leer la tabla necesitarás leer con cierto detenimiento ?read.table.
Ejercicio 1.16 Repite el ejercicio anterior eliminando la opción header = TRUE. Examina el resultado y comprueba que, efectivamente, los datos no se han cargado correctamente.
Ejercicio 1.17 Lee algún fichero de datos de tu interés y repite el ejercicio anterior.
Ejercicio 1.18 En read.table y sus derivados puedes indicar, además de ficheros disponibles en el disco duro, la URL de uno disponible en internet. Prueba a leer directamente el fichero disponible en https://datanalytics.com/uploads/datos_treemap.txt. Nota: es un fichero de texto separado por tabuladores y con nombres de columna.
Ejercicio 1.19 Alternativamente, si quieres leer un fichero remoto, puedes descargarlo directamente desde R. Consulta la ayuda de download.file para bajarte al disco duro el fichero del ejercicio anterior y leerlo después.
1.6 Gráficos básicos
Esta sección es una introducción a los gráficos básicos en R orientada a la inspección visual y rápida de conjuntos de datos, que es fundamental en todo proceso de análisis y, particularmente, en sus fases iniciales.
No nos preocuparemos demasiado de los aspectos estéticos de estos gráficos. En primer lugar, porque más adelante trataremos otros tipo de gráficos más sofisticados y atractivos estéticamente. Pero también porque los detalles sobre cómo modificar el aspecto de los gráficos es tan prolijo y lleno de detalles que es mejor omitirlo en una primera aproximación. Además, internet contiene seguramente la respuesta a cualquier pregunta que se te ocurra sobre cómo modificar los valores por defecto: ejes, orientación de etiquetas, etc. Es un campo amplio y lleno de detalles pero que es más bien material de consulta puntual en un momento de necesidad que de exposición exhaustiva en un texto introductorio.
En particular, en esta sección trataremos la manera de representar:
- Una variable continua
- Una variable categórica
- La relación entre dos variables continuas
- La relación entre una variable continua y otra categórica
1.6.1 Representación gráfica de variables continuas: histogramas
Nuestros datos pueden contener una columna como, por ejemplo, edad. En apartados anteriores hemos aprendido:
- cómo inspeccionar los valores extremos de esa variable (p.e., ordenando la tabla por edad y mostrando las primeras y las últimas filas con las funciones
headytail) por si, por ejemplo, existen edades negativas; - cómo obtener algunos estadísticos básicos de esa columna (usando
summarysobre la tabla).
Ejercicio 1.20 Inspecciona la columna Temp (temperatura) del conjunto de datos airquality de acuerdo con las sugerencias del párrafo anterior.
Sin embargo, es mucho más informativa una representación visual de los datos. La manera más rápida (y recomendada) de hacerse una idea de la distribución de los datos de una columna numérica es usando histogramas. En R, para representar el histograma de la columna Sepal.Width de iris se puede hacer:
hist(iris$Sepal.Width)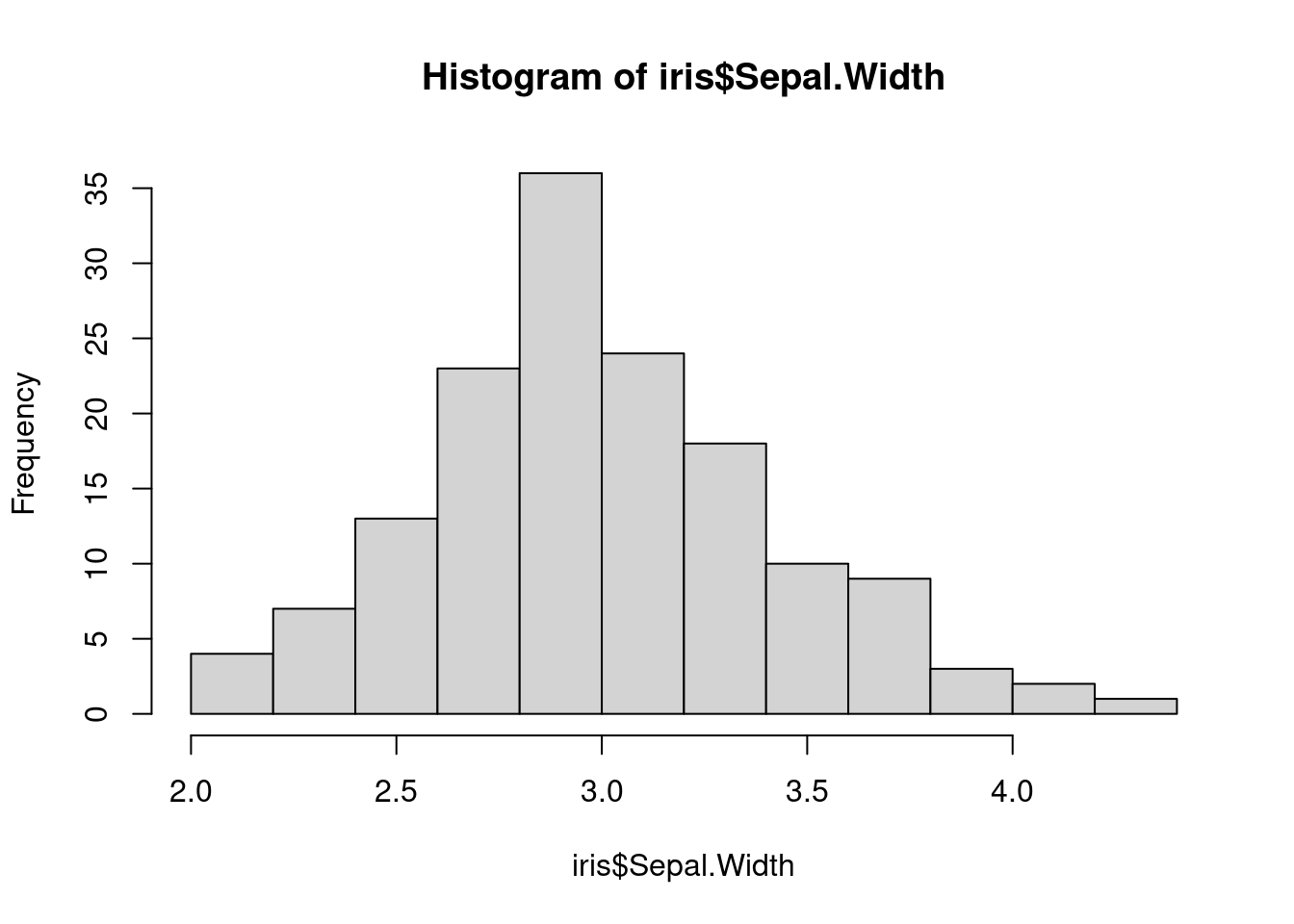
Esa es la orden básica. Pero los gráficos pueden ser modificados para incluir títulos, etiquetas, colores, etc. Por ejemplo,
hist(iris$Sepal.Width, main = "iris: histograma de la anchura de los sépalos",
xlab = "anchura del sépalo", ylab = "frecuencia",
col = "steelblue")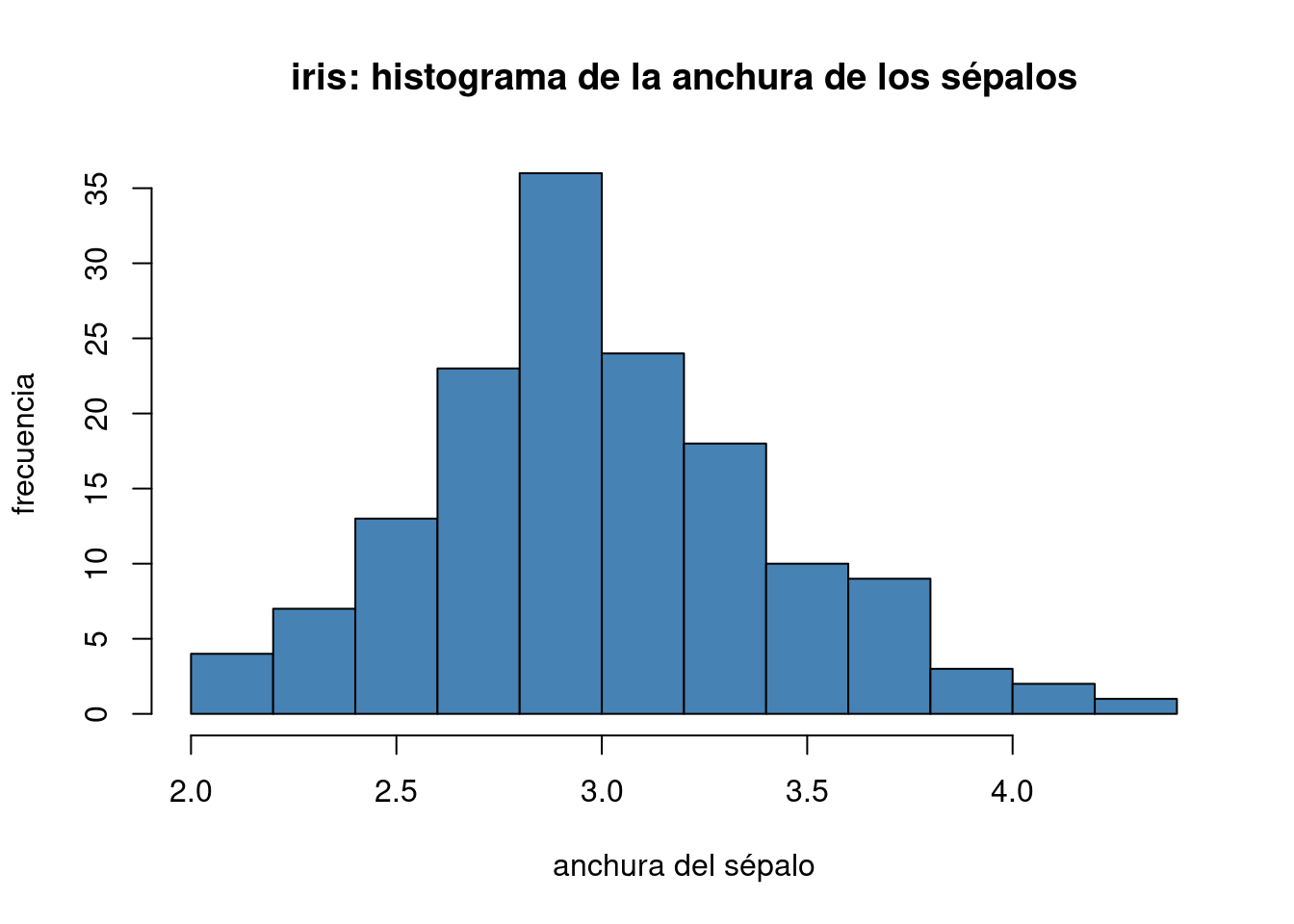
Los argumentos main, xlab, ylab y col10 se pueden aplicar también a otros gráficos que veremos a continuación.
Ejercicio 1.21 Por defecto, el eje horizontal de un histograma muestra el número de observaciones en cada bin. Examina ?hist para ver cómo mostrar en, lugar de los números absolutos, la proporción.
Ejercicio 1.22 El número de bins también es parametrizable. Examina otra vez la página de ayuda para modificar el valor por defecto.
Ejercicio 1.23 Estudia la distribución de las temperaturas en Nueva York (usa airquality).
Para guardar el gráfico, puedes usar los menús de Rstudio. Pero también puedes hacerlo programáticamente. En la página de ayuda de la función png se explica cómo hacerlo11.
Ejercicio 1.24 Usa las funciones png y jpeg para guardar alguno de los gráficos anteriores en tu disco duro.
1.6.2 Representación gráfica de variables categóricas: barras
En las tablas suelen coexistir variables continuas y categóricas. Por ejemplo, es interesante conocer la distribución (o frecuencia) de cada una de las categorías. Para eso se suelen usar los diagramas de barras; en particular, la función barplot de R.
Esta función no muestra directamente las frecuencias de una variable categórica. Es necesario calcular previamente dichas frecuencias, para lo cual usaremos la función table que se tratará con más detalle posteriormente.
Por ejemplo, la expresión siguiente muestra cómo en iris existe el mismo número de observaciones de cada especie:
barplot(table(iris$Species))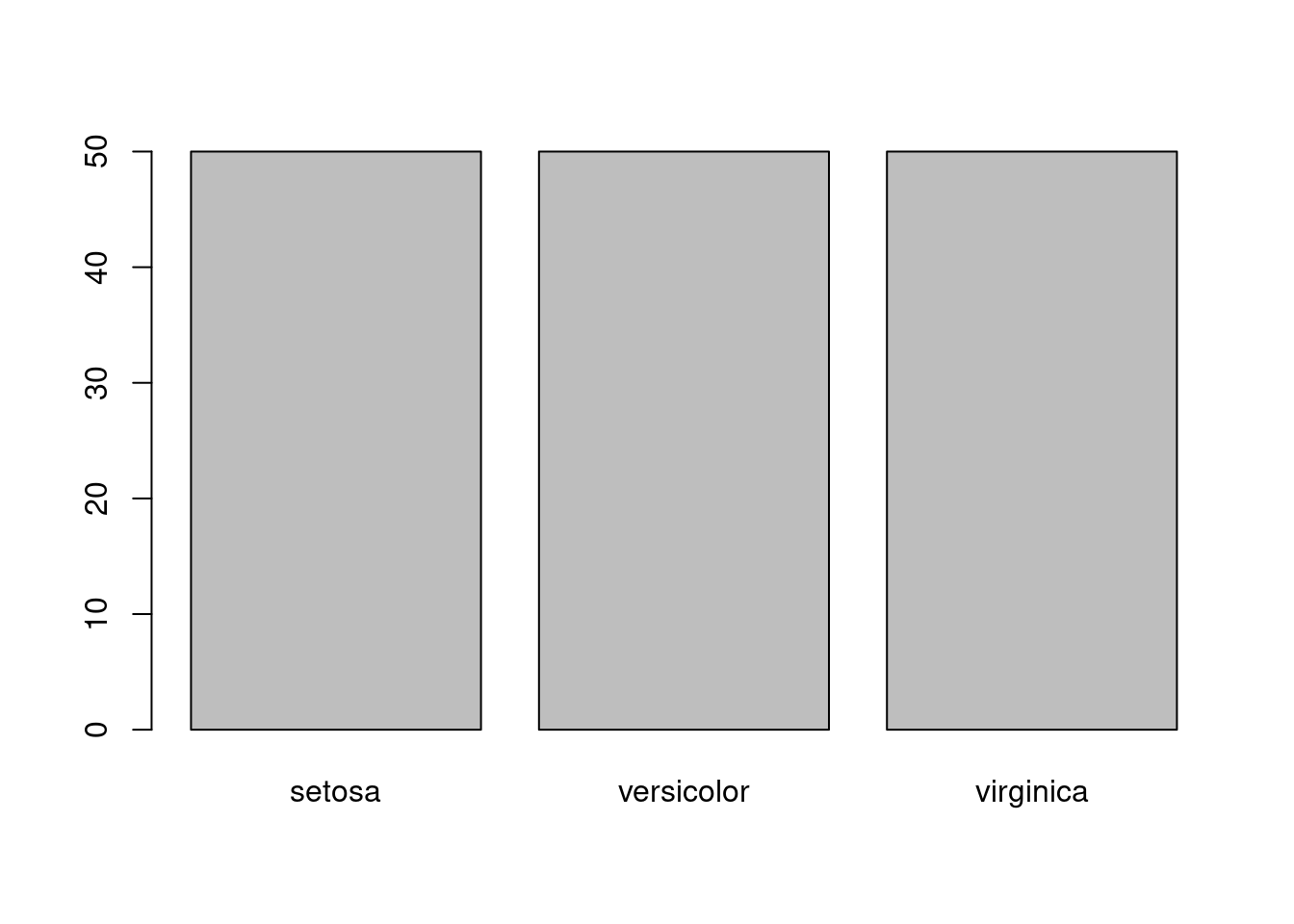
Ejercicio 1.25 Usa los parámetros main, xlab, ylab y col discutidos en la sección anterior para mejorar el aspecto de este gráfico.
Ejercicio 1.26 Investiga el argumento horiz de barplot para crear un gráfico de barras horizontales.
Los diagramas de barras también pueden usarse para mostrar datos contenidos en vectores etiquetados. De hecho, table crea un vector etiquetado: asocia a cada etiqueta su frecuencia en la columna. Algunas tablas contienen un registro por etiqueta y entonces podemos usar gráficos de barras para representar esa información. Por ejemplo:
barplot(VADeaths[, 2], xlab = "tramos de edad", ylab = "tasa de mortalidad",
main = "Tasa de mortalidad en Virginia\nmujer/rural")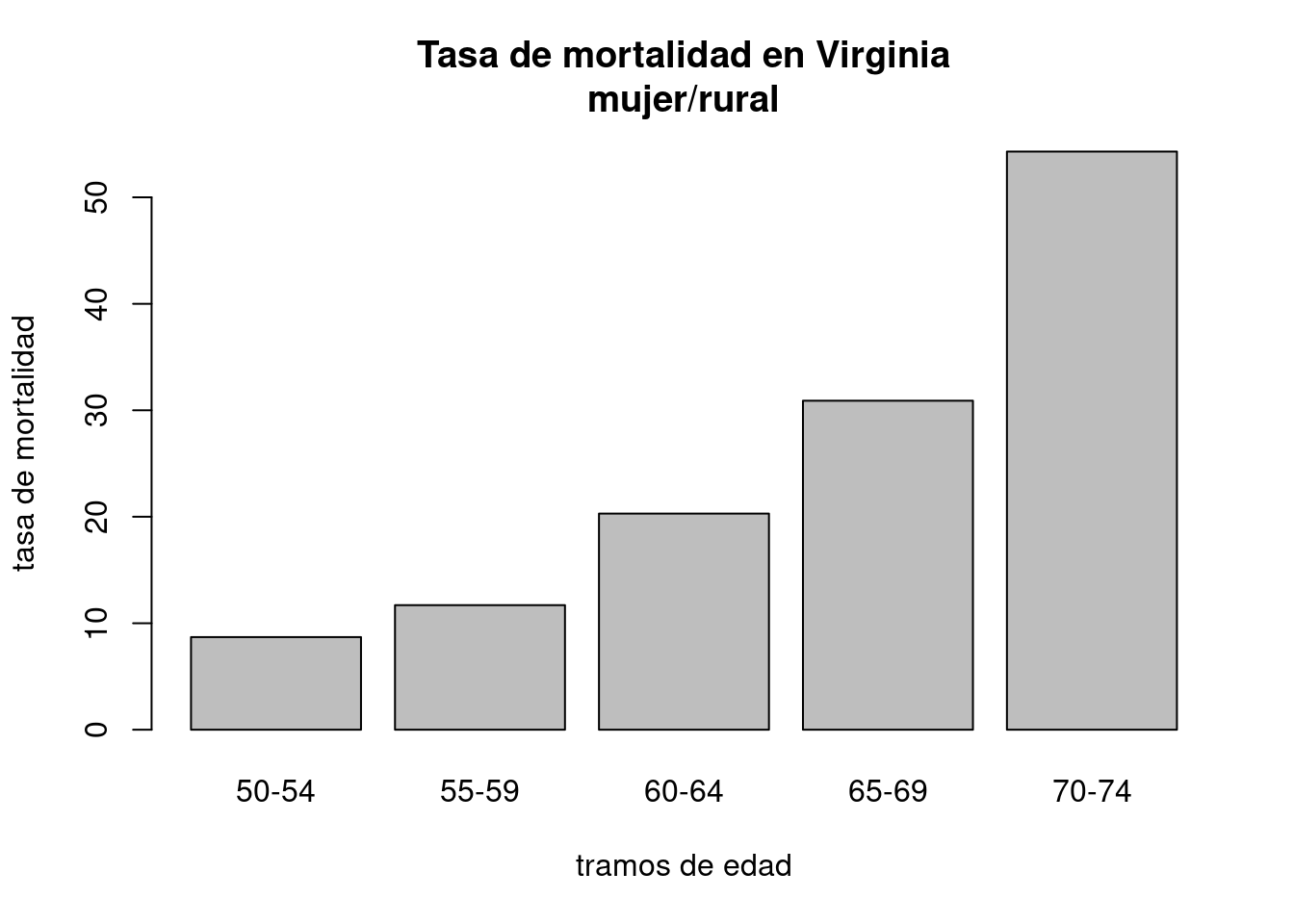
Los gráficos de barras son las representaciones más habituales para mostrar la distribución de vectores (entre ellos, las frecuencias de etiquetas). Sin embargo, existen alternativas modernas y superiores a ellos en algunos aspectos. Por ejemplo, los gráficos de puntos, implementados en R en la función dotchart.
1.6.3 Representación de la relación entre dos variables continuas: gráficos de dispersión
Los aspectos más interesantes de los datos se revelan no examinando las variables independientemente sino en relación con otras. Los gráficos de dispersión muestran la relación entre dos variables numéricas. En el ejemplo siguiente serán la velocidad y la distancia de frenado de un conjunto de coches recogidas en el conjunto de datos cars:
plot(cars$speed, cars$dist)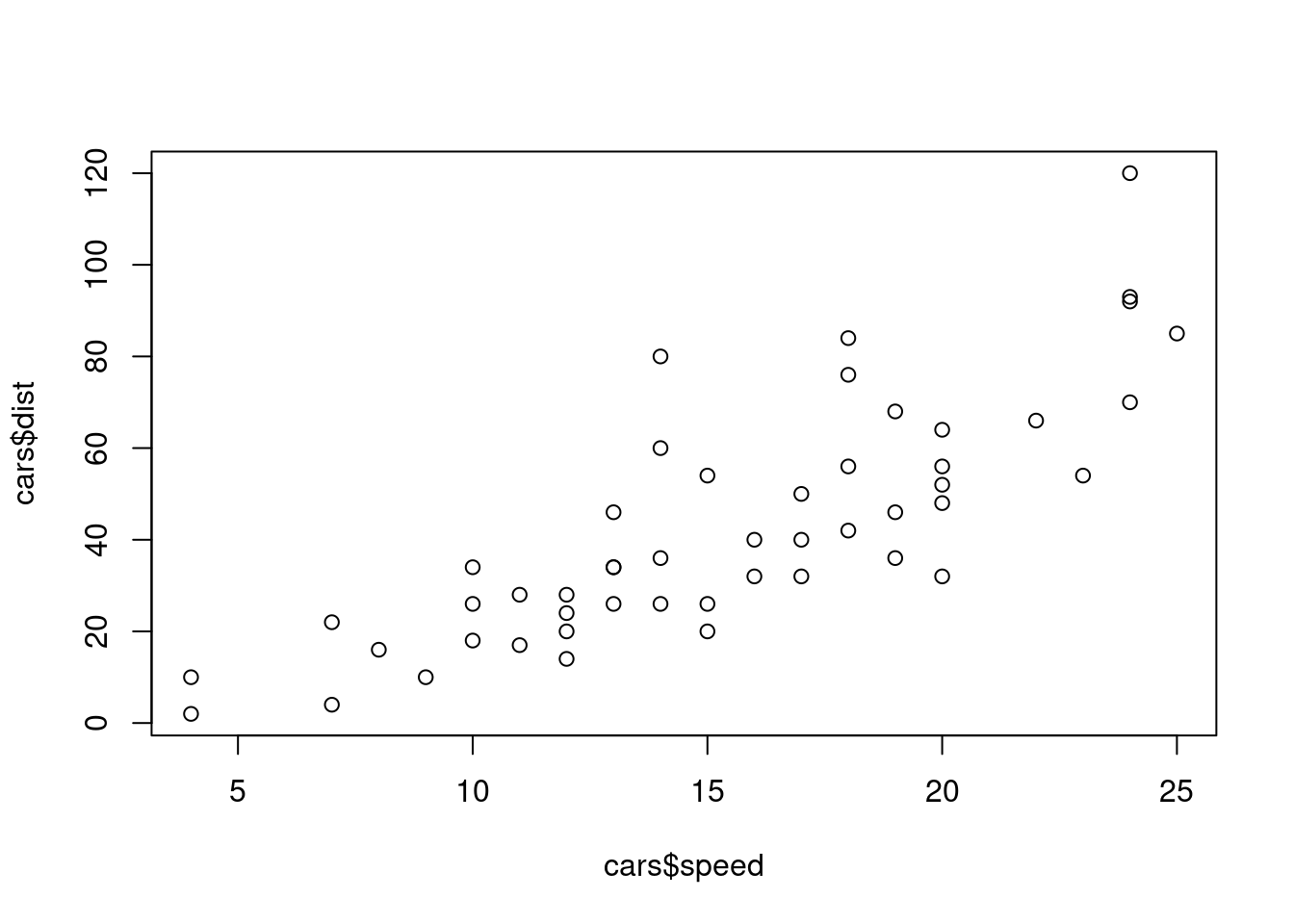
El gráfico muestra cómo aumenta dist en función de speed.
Ejercicio 1.27 Representa gráficamente la anchura del sépalo contra su longitud (usando iris). Interpreta el gráfico.
Ejercicio 1.28 De nuevo, usa los parámetros main, xlab, ylab y col discutidos en la sección anterior para mejorar el aspecto de los gráficos anteriores.
En ocasiones, cuando una de las variables tiene un orden determinado (por ejemplo, es una variable temporal) pueden utilizarse líneas para unir los puntos de un diagrama de dispersión (o, más habitualmente, reemplazarlos por ellas). Por ejemplo, utilizando el hecho de que las observaciones de airquality están ordenadas temporalmente, podemos representar la temperatura en periodo que comprende así:
plot(airquality$Temp, type = "l")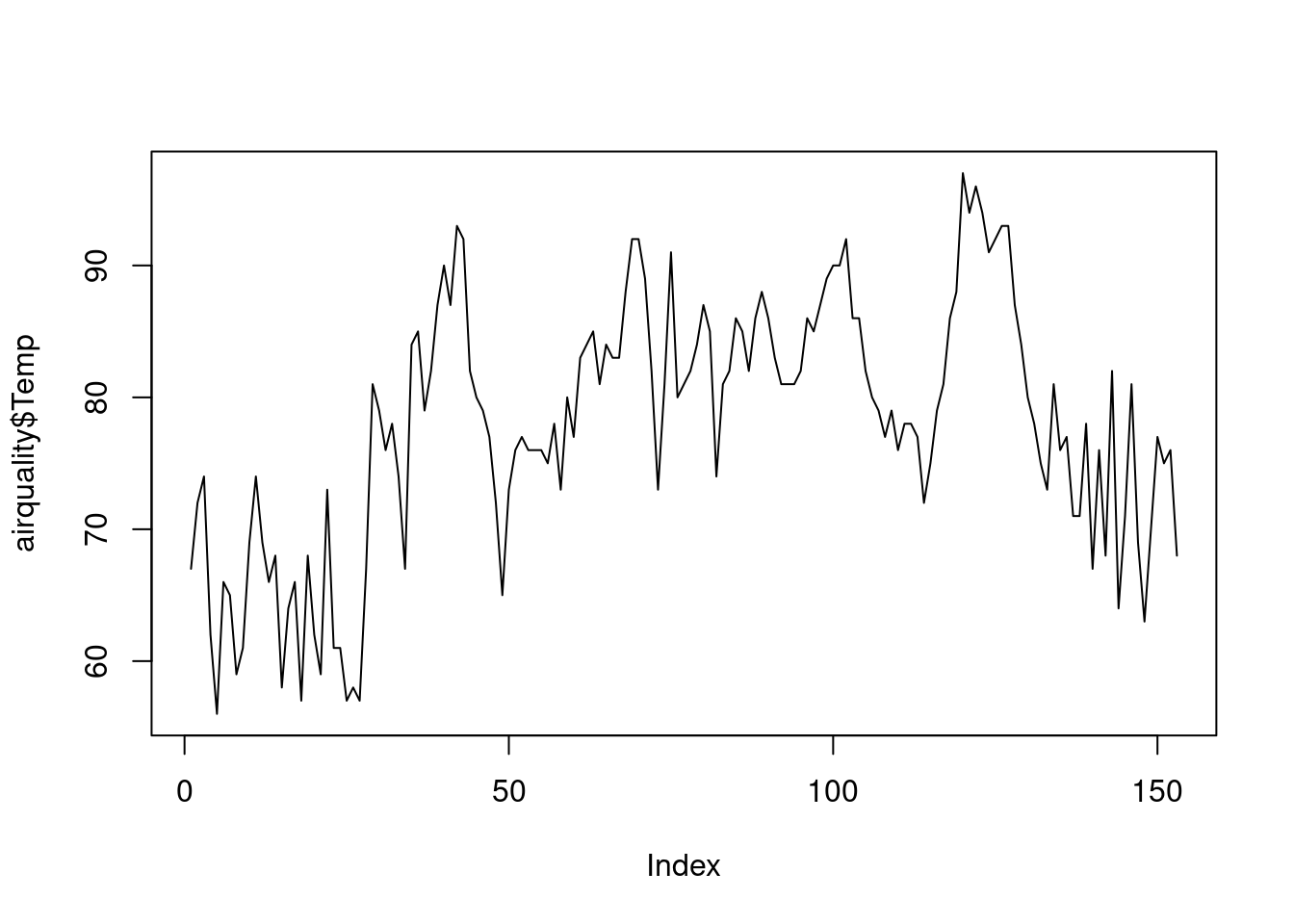
Incluso, se pueden combinar varios elementos gráficos sobre la misma representación gráfica: por ejemplo, combinar puntos y líneas como aquí:
plot(airquality$Temp)
lines(airquality$Temp)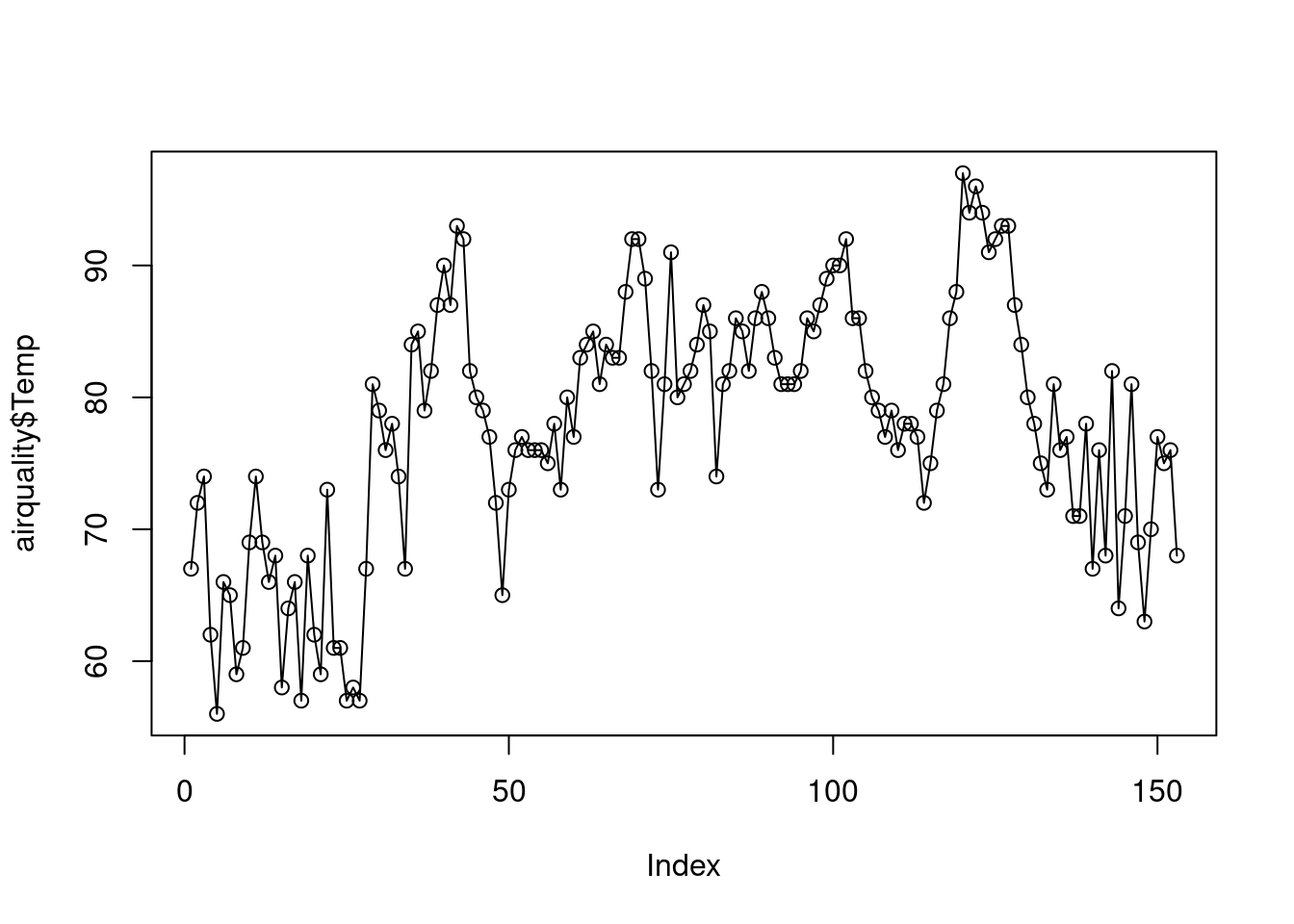
El anterior es un ejemplo de una característica de los gráficos básicos de R: a un primer gráfico se le pueden añadir progresivamente capas adicionales. En el caso anterior, a un gráfico de puntos se le han añadido líneas. Pero podrían añadirse más elementos. Por ejemplo, al gráfico anterior se le puede añadir un elemento más, una línea horizontal roja a la altura de la temperatura media, usando la función (muy útil) abline:
plot(airquality$Temp)
lines(airquality$Temp)
abline(h = mean(airquality$Temp), col = "red")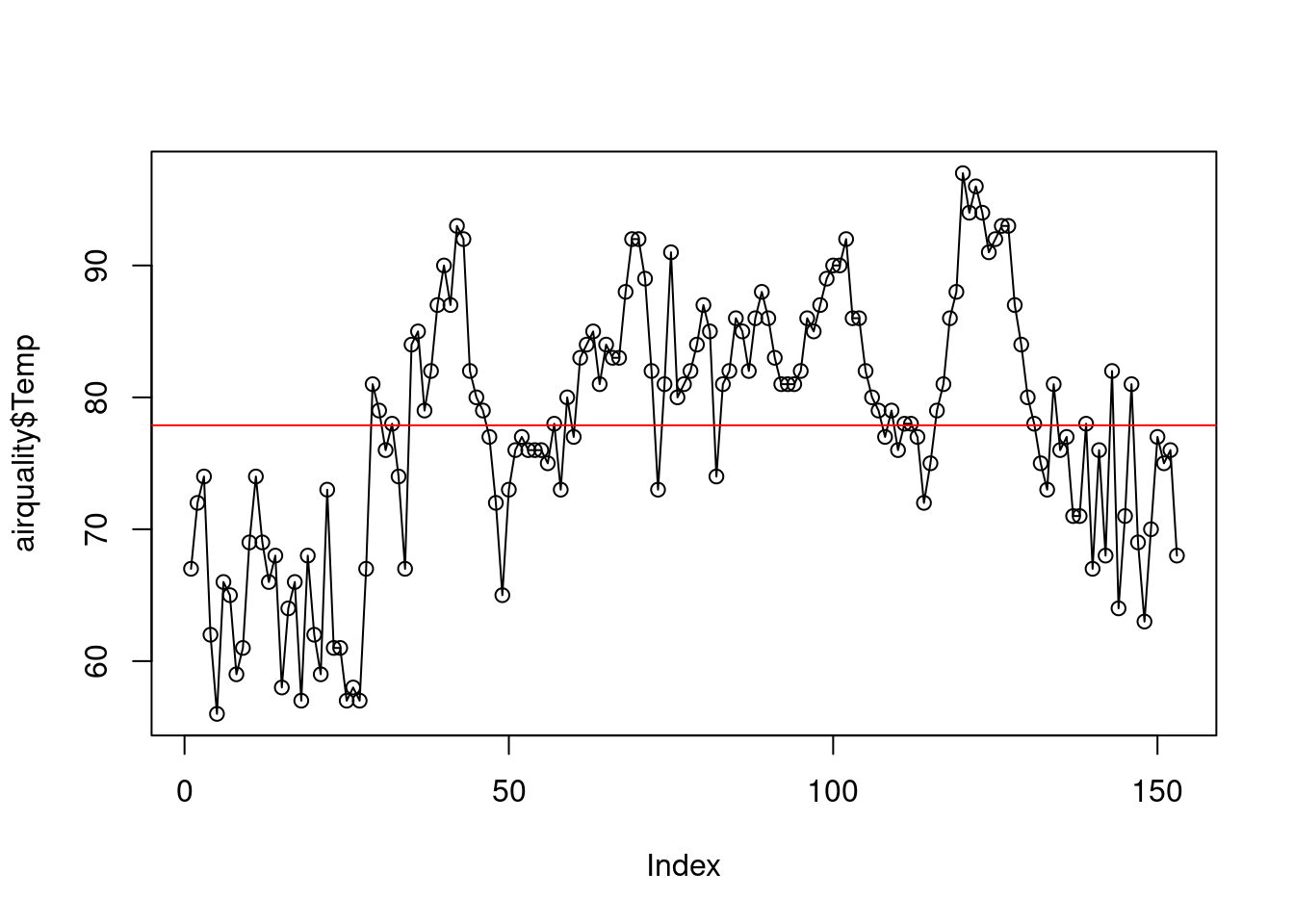
Ejercicio 1.29 Consulta la ayuda de la función abline y úsala para añadir líneas (no solo horizontales) a alguno de los gráficos anteriores.
Ejercicio 1.30 Consulta ?par, una página de ayuda en R que muestra gran cantidad de parámetros modificables en un gráfico. Investiga y usa col, lty y lwd. Nota: casi nadie conoce estos parámetros y, menos, de memoria; pero está bien saber que existen por si un día procede utilizarlos.
1.6.4 Representación de la relación entre una variable continua y otra categórica: diagramas de caja (boxplots)
Los diagramas de cajas (boxplot) estudian la distribución de una variable continua en función de una variable categórica. Están emparentados con los histogramas porque resumen la distribución de una variable continua. Para ello utilizan una representación todavía mas esquemática que la de un histograma: una caja y unos segmentos que acotan las regiones donde la variable continua concentra el grueso de las observaciones.
Por ejemplo, podemos estudiar la distribución de la anchura del sépalo en iris en función de la especie usando diagramas de cajas así:
boxplot(iris$Sepal.Width ~ iris$Species, col = "gray",
main = "Especies de iris\nsegún la anchura del sépalo")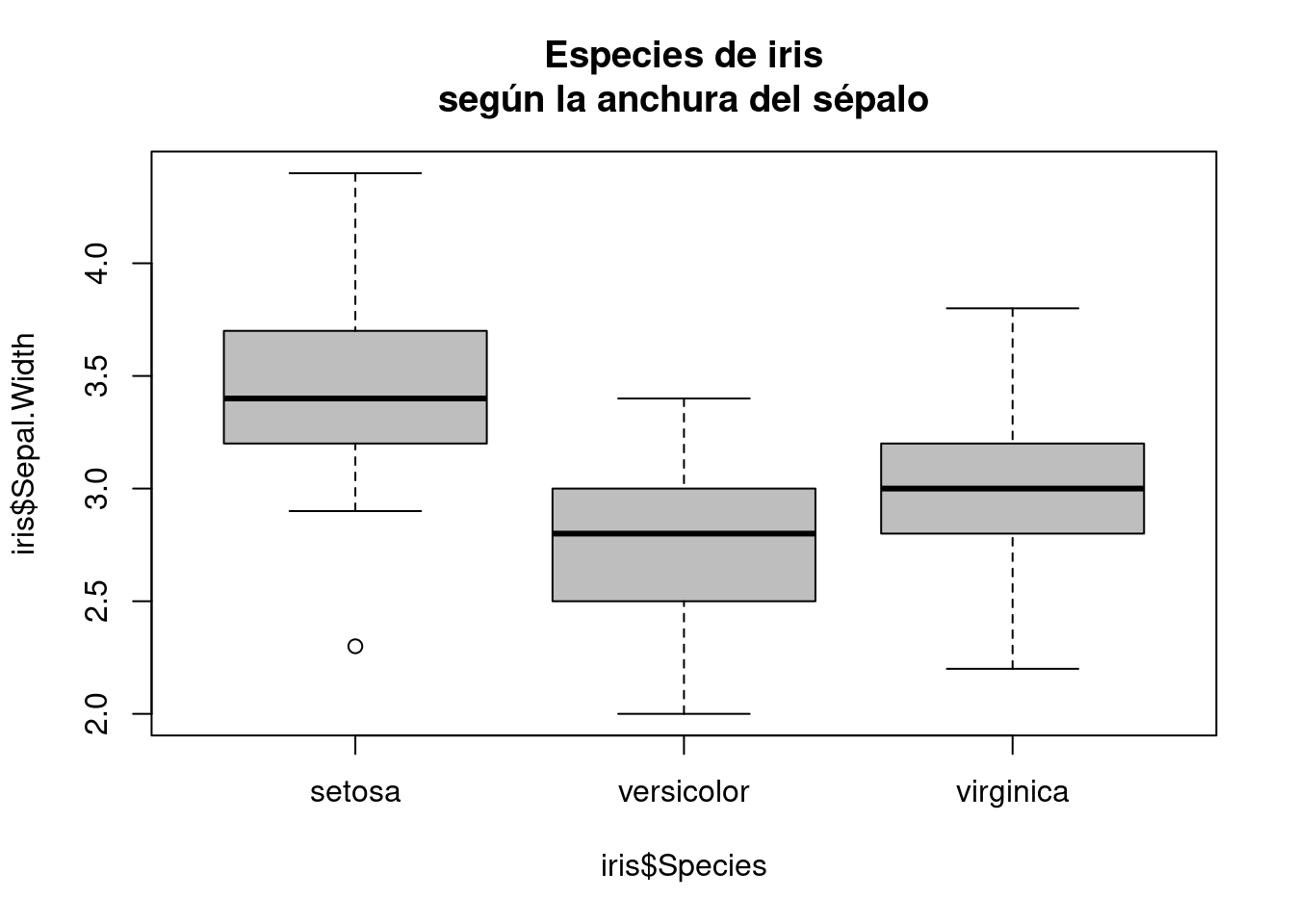
La notación y ~ x es muy común en R y significa que vas a hacer algo con y en función de x; en este caso, algo es un diagrama de cajas. Cuando construyamos modelos, querremos entender la variable objetivo y en función de una o más variables predictoras y volveremos a hacer uso de esa notación12.
El gráfico anterior ilustra la potencia de los diagramas de caja. Para las setosas, existe una observación atípica, mucho menor que el resto, pero cuya atipicidad queda oculta por otras observaciones normales correspondientes a virgínicas o versicolores. Esa observación atípica no llamaría la atención si se representan gráficamente todos los valores, independientemente de su tipo, pero se manifiesta claramente al segmentar la representación por especie.
Ejercicio 1.31 Identifica la observación atípica. ¿Es atípica también con respecto a otras variables?
Ejercicio 1.32 Muestra la distribución de las temperaturas en Nueva York en función del mes.
1.7 Resumen y referencias
Las tablas son las estructuras más habituales de la ciencia de datos. En R, a diferencia de otros lenguajes de programación, como Python o Java, son objetos nativos. En esta sección nos hemos familiarizado con los rudimentos del manejo de tablas en R: inspección de sus contenidos, ordenación, creación y borrado de columnas adicionales, etc. Esencialmente, aquellas que la mayoría hemos hecho ya previamente con herramientas tales como Excel.
Las tablas son fundamentales en R y en todas las secciones siguientes. Es muy importante adquirir una mínima soltura en su manejo. Gran parte de las secciones posteriores, de hecho, tratarán esencialmente sobre técnicas para procesar datos en tablas con extendiendo las planteadas en esta sección.
Python tiene tablas similares a las de R gracias a la librería Pandas. Puedes echarle un vistazo al tutorial 10 minutes to Pandas para comparar las implementaciones. Debería resultarte familiar.
Finalmente, existen muchos tutoriales que profundizan en los detalles de los gráficos básicos de R. Por ejemplo, este.
1.8 Ejercicios adicionales
Ejercicio 1.33 Usa iris para explorar qué pasa cuando usas head y tail con un argumento negativo.
Ejercicio 1.34 Usando airquality:
- ¿cuál fue la temperatura media de los días que contiene?
- ¿cuál fue la temperatura media en mayo?
- ¿cuál fue el día más ventoso?
Ejercicio 1.35 Crea una tabla adicional seleccionando todas las columnas menos mes y día; luego haz un plot de ella y trata de encontrar relaciones (cualitativas) entre la temperatura y el viento, o el ozono,…
Ejercicio 1.36 Usando el conjunto de datos mtcars (consulta ?mtcars), averigua:
- cuál es el modelo que menos consume
- cuál es el consumo medio de los modelos de 4 cilindros
Ejercicio 1.37 Crea un histograma de la temperatura en Nueva York (usando airquality) y después usa abline para dibujar una línea vertical roja en la media de la distribución. Puedes obtener la media con summary o bien aplicando la función mean a la columna de interés.
Ejercicio 1.38 Carga el fichero pisasci2006.csv que contiene los promedios de los resultados en ciencia notas por país en las pruebas PISA de 2006. Con él:
- identifica y muestra la línea correspondiente a España
- haz una gráfica en que se muestre la nota en función de los ingresos
- identifica el outlier en la gráfica anterior: ¿a qué país corresponde?
- construye un histograma con la nota y añade una recta vertical roja en la correspondiente a España
Este conjunto de datos tiene una larga historia (fue publicado originalmente en 1935) y se ha venido utilizando para ilustrar el uso de ciertos modelos estadísticos de clasificación.↩︎
O, si la línea aparece en un programa, colocando el cursor en cualquier punto de ella y pulsando
Control-Enter.↩︎También se puede escribir
help(summary), pero es más largo y nadie lo hace.↩︎No es ortotipográficamente correcto usar negritas de esta manera; sin embargo, es tan importante recordarlo que, por una vez, el autor se saltará la norma.↩︎
Porque dentro del corchete podremos utilizar un vector de nombres o números e columnas.↩︎
Existe una función,
transformque también puede usarse para transformar tablas, en el sentido de añadirle nuevas columnas, que veremos más adelante.↩︎Aunque más adelante veremos extensiones que sí permiten hacerlo↩︎
Existen versiones de
read.table, comoread.csvoread.csv2, que son la misma función pero con valores por defecto distintos para poder leer (a menudo) directamente ficheros con formatocsvy otros. Pero, en el fondo, no dejan de ser alias deread.table.↩︎Notepad no es un editor de texto decente.↩︎
En el ejemplo anterior se ha usado el color
steelblue. Si buscas en internet encontrarás la lista completa de aquellos colores cuyos nombres entiende R o cómo usar sus representaciones RGB u otras.↩︎Seguro, entenderás mejor los ejemplos de esa página que el mismo cuerpo de la documentación↩︎
En R existe un tipo de datos muy especial:
formula; sirve para especificar relaciones entre variables y aunque fue creado para especificar modelos estadísticos, se utiliza frecuentemente en otros contextos.↩︎