Esta sección muestra cómo aplicar una serie de técnicas estadísticas habituales con R como ejercicio de lo aprendido en los capítulos anteriores y como motivación para introducir otros conceptos más adelante. Probablemente, ayudará a satisfacer la curiosidad de quienes ya las conozcan y quieran ver cómo utilizarlas en R. En todo caso, esta sección renuncia absolutamente a profundizar en sus aspectos matemáticos.
3.1 El test de Student
El test de Student es la contraparte estadística al diagrama de cajas. Si estos permiten comparar gráficamente, i.e. cualitativamente, dos (o más) distribuciones, el test de Student permite cuantificar de alguna manera esa diferencia.
Para ilustrar el uso del test de Student vamos a analizar el conjunto de datos sleep:
summary(sleep)
extra group ID
Min. :-1.600 1:10 1 :2
1st Qu.:-0.025 2:10 2 :2
Median : 0.950 3 :2
Mean : 1.540 4 :2
3rd Qu.: 3.400 5 :2
Max. : 5.500 6 :2
(Other):8
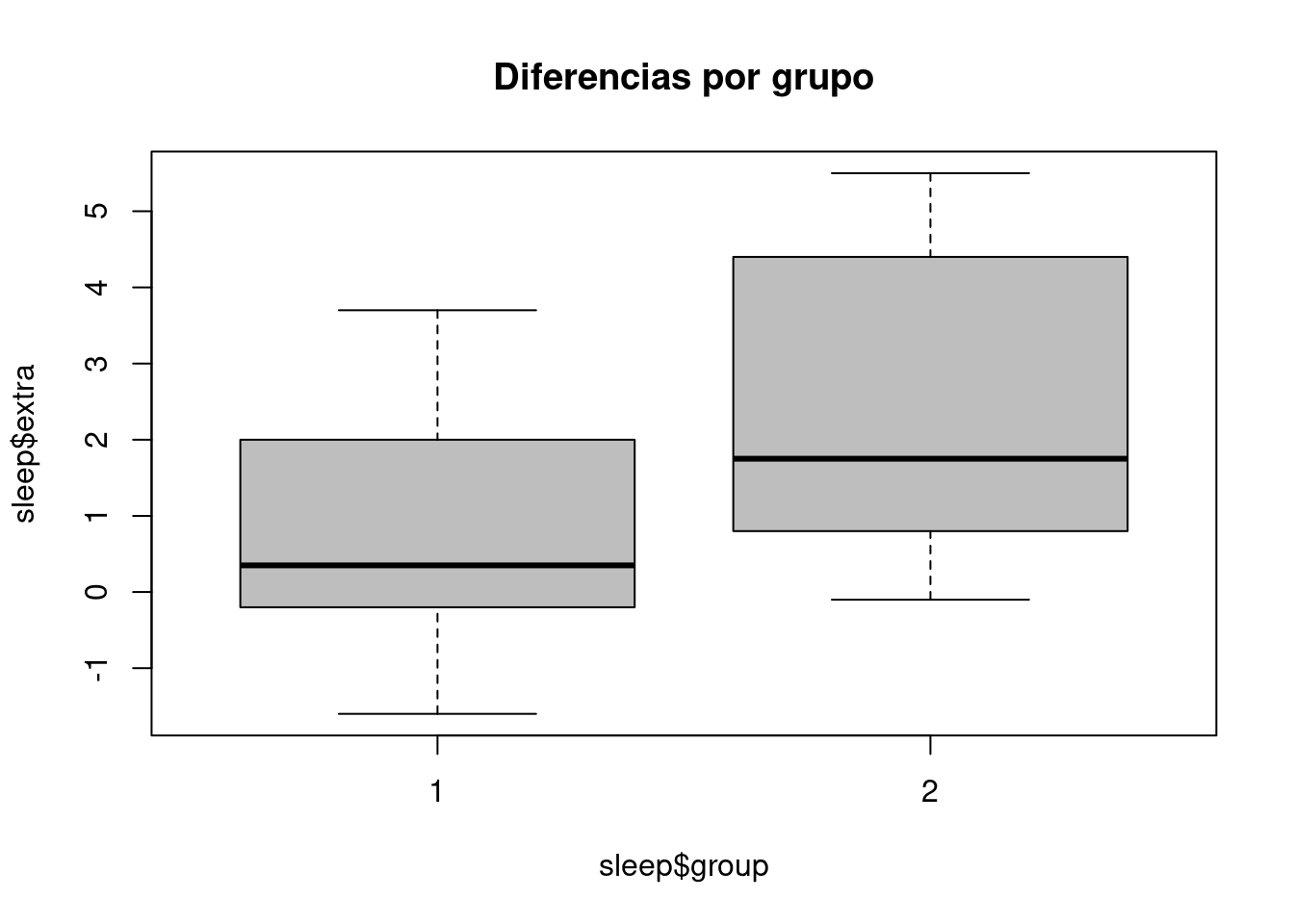
sleep contiene información sobre el número adicional de horas que durmieron una serie de sujetos después de recibir un determinado tratamiento médico. Los vamos a comparar con otros sujetos, los del grupo de control, que recibieron un placebo. El siguiente diagrama de cajas muestra la distribución del número de horas de sueño con y sin tratamiento.
boxplot(sleep$extra ~ sleep$group, col ="gray",main ="Diferencias por grupo")
Este gráfico muestra cómo el grupo tratado, el de la derecha, tiende a dormir más horas. Pero no responde fehacientemente a la pregunta de si el tratamiento funciona o no. El llamado test de Student ayuda a determinar si la diferencia observada es o no estadísticamente significativa. Nótese cómo su sintaxis es esencialmente la misma que la de boxplot:
t.test(sleep$extra ~ sleep$group)
Welch Two Sample t-test
data: sleep$extra by sleep$group
t = -1.8608, df = 17.776, p-value = 0.07939
alternative hypothesis: true difference in means between group 1 and group 2 is not equal to 0
95 percent confidence interval:
-3.3654832 0.2054832
sample estimates:
mean in group 1 mean in group 2
0.75 2.33
La salida de la expresión anterior es la que normalmente reproducen los artículos científicos cuando se aplica esta técnica. El indicador más importante (aunque cada vez más cuestionado) es el llamado p-valor y una regla de decisión habitual es dar por estadísticamnete significativo el efecto del tratamiento cuando este es inferior a 0.05. En este caso, el p-valor es de 0.07 por lo que se consideraría que no existe diferencia significativa entre los grupos.
Ejercicio 3.1 El test de Student no se puede aplicar a cualquier tipo de datos. Estos tienen que cumplir una serie de condiciones. Cuando las pruebas previas parecen indicar que no dichas condiciones no se cumplen, los manuales recomiendan utilizar una alternativa no paramétrica, la del Wilcoxon. Aplícasela a estos datos comprueba el p-valor obtenido. Nota: en R, es el wilcox.test.
Existen muchas más pruebas estadísticas en R. Que la sintaxis de las dos anteriores (la de t.test y de wilcox.test) sea similar no es casualidad: la de todas las funciones que que aplican pruebas estadísticas en R es homogénea y predecible.
Ejercicio 3.2 Estudia los ejemplos de prop.test, que implementa una prueba estadística para comprobar si dos proporciones son o no significativamente distintas.
3.2 Regresión lineal
La regresión lineal expresa la relación entre una variable numérica con otras variables predictoras. En el caso más simple, el que vamos a explorar a continuación, se considera una única variable predictora.
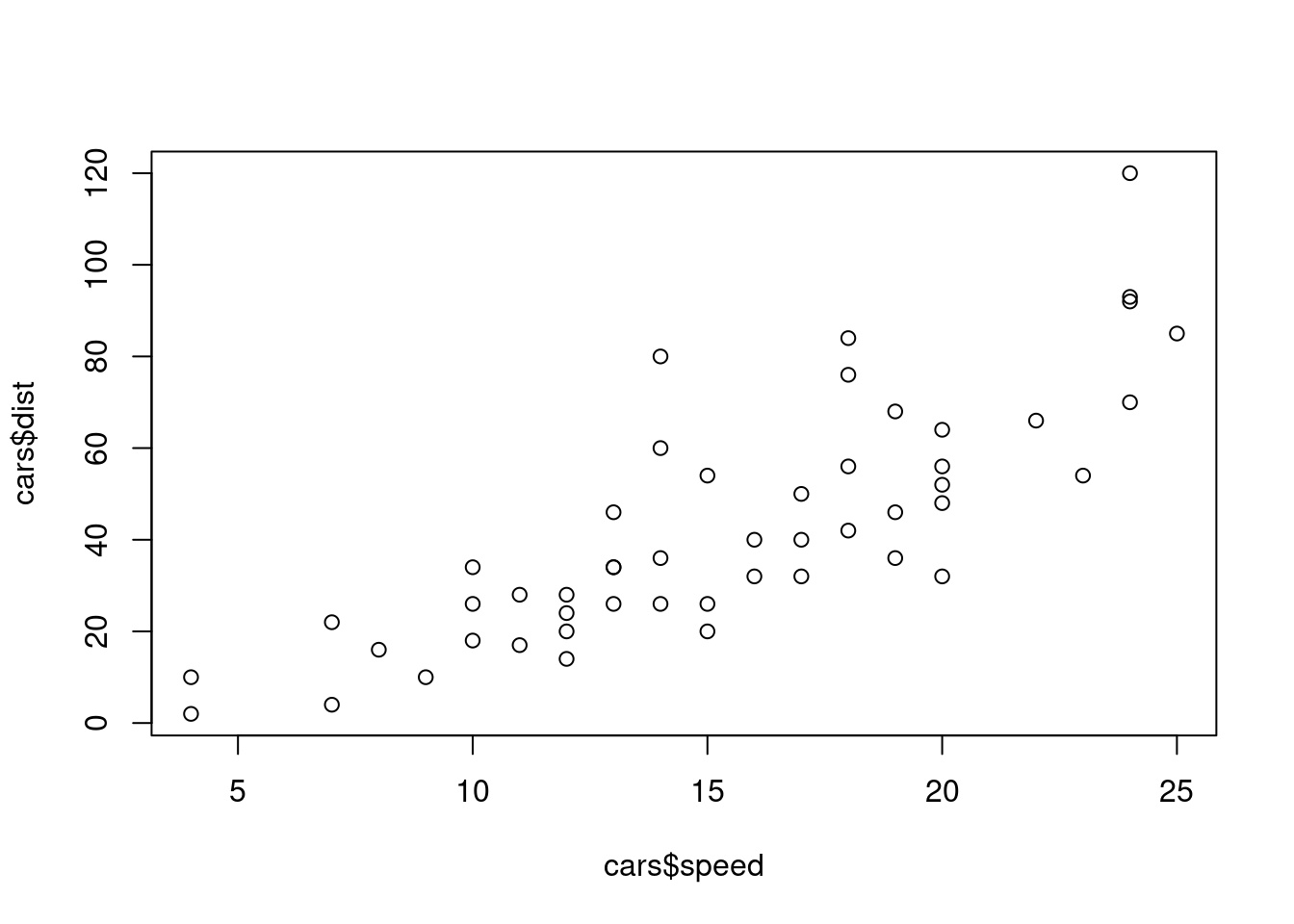
Existe una relación creciente entre las variables velocidad y distancia en el conjunto de datos cars. En efecto, a mayor velocidad, mayor es la distancia de frenado de los vehículos:
plot(cars$speed, cars$dist)
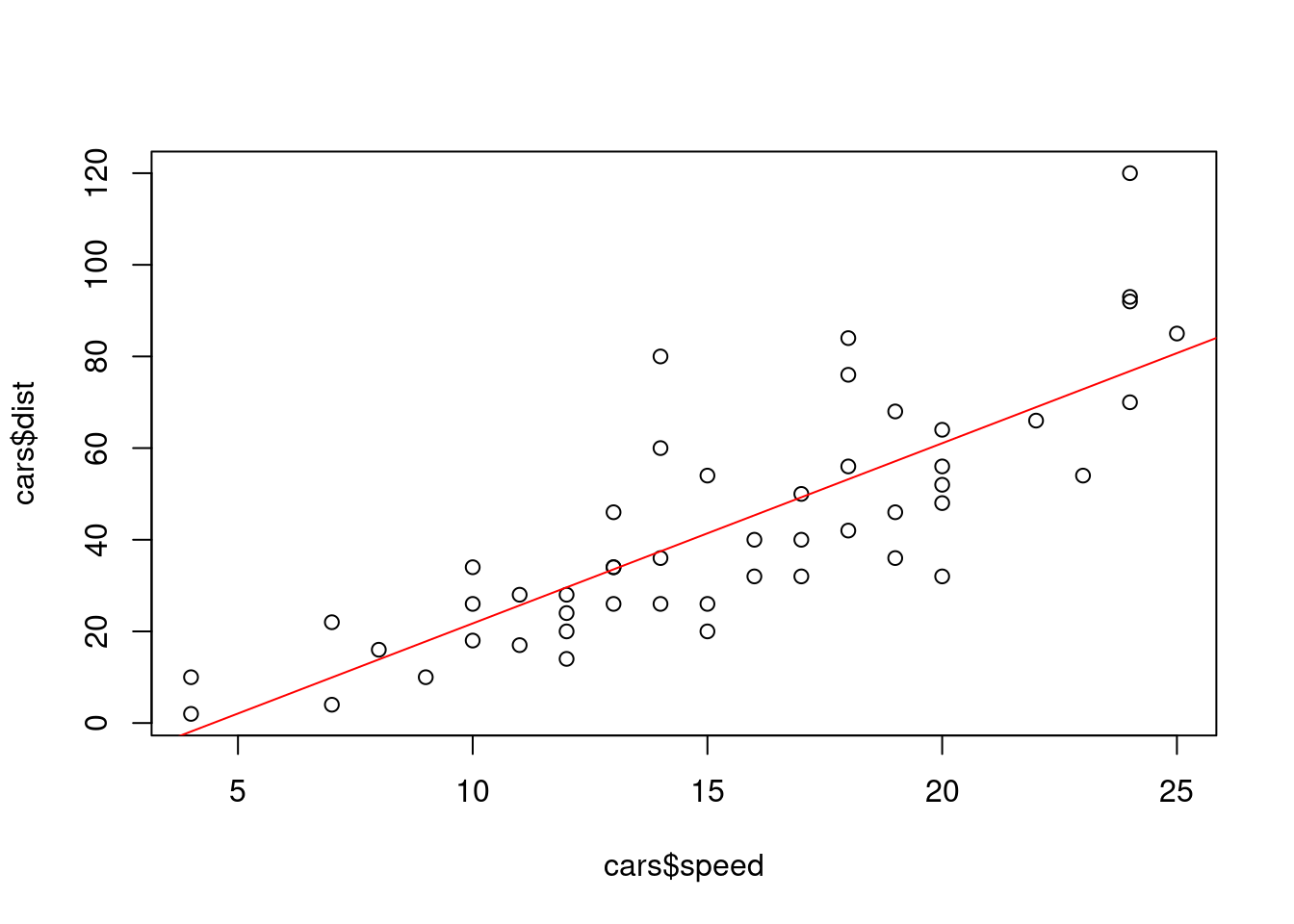
El gráfico anterior muestra una nube de puntos. La regresión lineal construye la recta que, en cierto modo, mejor aproxima esa nube.
plot(cars$speed, cars$dist)abline(lm.dist.speed, col ="red")
El código precedente usa la función lm para ajustar el modelo de regresión lineal (linear model), muestra un pequeño resumen del modelo en pantalla y finalmente añade la recta de regresión, en rojo, al gráfico anterior.
La función summary, aplicada en este caso no a un vector o a una tabla sino al objeto resultante de la regresión lineal, muestra un resumen del modelo similar al que aparece en las publicaciones científicas:
summary(lm.dist.speed)
Call:
lm(formula = cars$dist ~ cars$speed)
Residuals:
Min 1Q Median 3Q Max
-29.069 -9.525 -2.272 9.215 43.201
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -17.5791 6.7584 -2.601 0.0123 *
cars$speed 3.9324 0.4155 9.464 1.49e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 15.38 on 48 degrees of freedom
Multiple R-squared: 0.6511, Adjusted R-squared: 0.6438
F-statistic: 89.57 on 1 and 48 DF, p-value: 1.49e-12
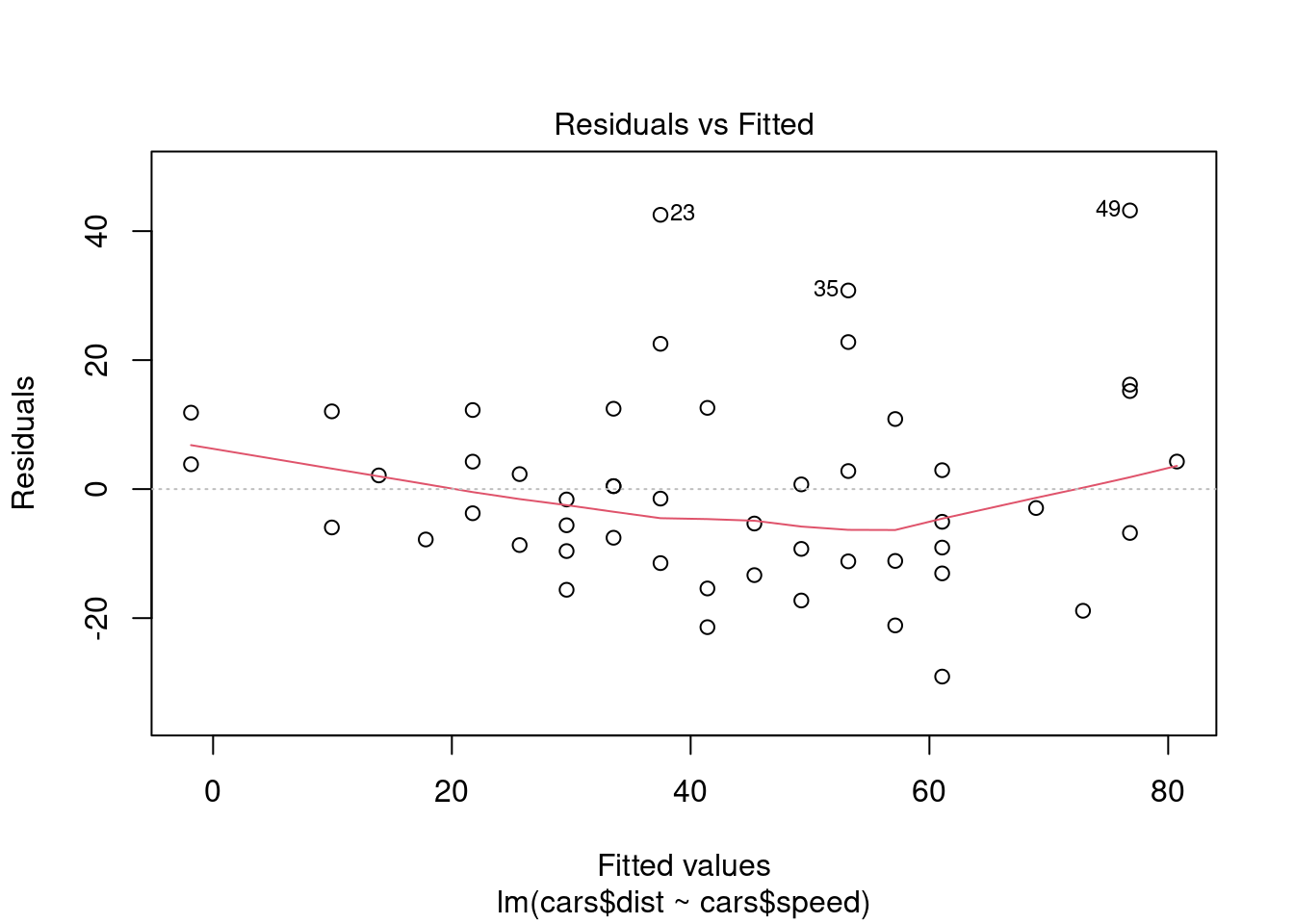
summary no es la única función que admite el modelo creado: plot crea una representación gráfica (de hecho, produce varias gráficas distintas de las que en el código que aparece a continuación representaremos solo la primera; para ver las restantes, cambia el índice 1 por otros valores entre 2 y 6) que ilustra algunos aspectos del modelo que los implementadores de la función lm encontraron útiles:
plot(lm.dist.speed, 1)
En general, muchos modelos creados en R admiten llamadas de las funciones summary y plot, que producen los resultados esperados.
Ejercicio 3.3 Haz una regresión del nivel de ozono sobre la temperatura en Nueva York. Crea el gráfico de dispersión y añádele la recta de regresión (en rojo u otro color distinto del negro) con abline.
3.3 Regresión logística
La regresión logística forma parte de los llamados modelos lineales generalizados y trata de estimar la probabilidad de ocurrencia de un evento binario (éxito/fracaso, cara/cruz) en función de una serie de variables predictoras.
En el ejemplo siguiente, usaremos el conjunto de datos UCBAdmissions y el evento binario es la admisión de un estudiante a un programa de doctorado en función otras variables.
datos <-as.data.frame(UCBAdmissions)datos$Admit <- datos$Admit =="Admitted"
Este conjunto de datos se recogió para un estudio acerca de la discriminación contra las mujeres en este tipo de ámbitos publicado por Science en 1975. Por eso interesa conocer el efecto de la variable Gender en la probabilidad de resultar admitido.
Por lo tanto, en primer lugar, vamos a probar un modelo usando exclusivamente dicha variable:
Call:
glm(formula = Admit ~ Gender, family = binomial(), data = datos,
weights = Freq)
Deviance Residuals:
Min 1Q Median 3Q Max
-20.336 -15.244 1.781 14.662 28.787
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.22013 0.03879 -5.675 1.38e-08 ***
GenderFemale -0.61035 0.06389 -9.553 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 6044.3 on 23 degrees of freedom
Residual deviance: 5950.9 on 22 degrees of freedom
AIC: 5954.9
Number of Fisher Scoring iterations: 4
Se aprecia en el resumen del modelo cómo el sexo es una variable predictora muy importante (el p-valor es ínfimo y el tamaño del coeficiente relativamente grande) y cómo da la impresión de que en el proceso de admisión existe discriminación contra las mujeres: el coeficiente es negativo.
El siguiente modelo incluye el departamento como variable predictora. En el resultado se aprecia cómo el efecto del sexo prácticamente desaparece.
Call:
glm(formula = Admit ~ Gender + Dept, family = binomial(), data = datos,
weights = Freq)
Deviance Residuals:
Min 1Q Median 3Q Max
-25.3424 -13.0584 -0.1631 16.0167 21.3199
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.58205 0.06899 8.436 <2e-16 ***
GenderFemale 0.09987 0.08085 1.235 0.217
DeptB -0.04340 0.10984 -0.395 0.693
DeptC -1.26260 0.10663 -11.841 <2e-16 ***
DeptD -1.29461 0.10582 -12.234 <2e-16 ***
DeptE -1.73931 0.12611 -13.792 <2e-16 ***
DeptF -3.30648 0.16998 -19.452 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 6044.3 on 23 degrees of freedom
Residual deviance: 5187.5 on 17 degrees of freedom
AIC: 5201.5
Number of Fisher Scoring iterations: 6
Lo que evidencia este segundo modelo es que no existía tal discriminación contra las mujeres. Lo que ocurría realmente es que los distintos departamentos tenían niveles de exigencia distintos y entre los candidatos a los más exigentes predominaban las mujeres. Las tasas de admitidos en cada departamento por sexo eran similares pero, globalmente, parecía haber un sesgo. Este es un ejemplo de libro de la llamada paradoja de Simpson.
De hecho, los autores del artículo mencionado más arriba lo resumieron así:
Measuring bias is harder than is usually assumed, and the evidence is sometimes contrary to expectation.
Ejercicio 3.4 El primer modelo, esencialmente, compara dos proporciones: el de hombres y mujeres admitidos. Utiliza la prueba de proporciones (prop.test en R) para compararlas de otra manera. ¿Coinciden los resultados? (Nota: no intentes este ejercicio salvo que tengas un interés particular en los métodos estadísticos y entiendas claramente qué se está pidiendo aquí.)
3.4 Resumen y referencias
En esta sección hemos visto cómo aplicar algunos métodos estadísticos habituales en R. Son solo tres de los cientos disponibles en R. La buena noticia es que prácticamente todos tienen una interfaz similar y familiar en R. Las malas noticias son dos:
Es arriesgado utilizar métodos estadísticos sin conocer bien sus fundamentos y tener claro qué hacen. Además, eso no se va a tratar en este libro.
Antes de poder aplicar cualquier método estadístico existe un trabajo previo de selección, limpieza y tratamiento de datos que es tan poco vistoso como, a medio plazo, aburrido. Ese es, fundamentalmente, el objetivo del libro.
Existen muchas fuentes para ahondar en el estudio de la estadística y los métodos estadísticos en R. Algunas se ofrecen en la [sección de referencias del capítulo dedicado a la estadística][refs_statistics].