Porque resulta que los hay de varios tipos. En R, hasta nueve de ellos:
set.seed(1234)
muestra <- sort(rt(100, 3))
mis.cuantiles <- sapply(1:9, function(tipo) quantile(muestra, 0.834, type = tipo))
mis.cuantiles
# 83.4% 83.4% 83.4% 83.4% 83.4% 83.4% 83.4% 83.4% 83.4%
#0.9065024 0.9065024 0.8951710 0.8997036 0.9053693 0.9331290 0.9015846 0.9077920 0.9063154Las definiciones de todos ellos pueden consultarse en Sample Quantiles in Statistical Packages.
Las diferencias entre ellos, de todos modos, decrecen conforme aumenta el tamaño muestral:
n.obs <- seq(100, 1e5, by = 1e3)
res <- sapply(n.obs, function(n){
x <- rt(n, 3)
diff(range(sapply(1:9, function(tipo)
quantile(x, 0.834, type = tipo))))
})
plot(n.obs, log10(res), type = "l",
xlab = "n obs", ylab = "discrepancia",
main = "Diferencias entre los distintos tipos de cuantiles")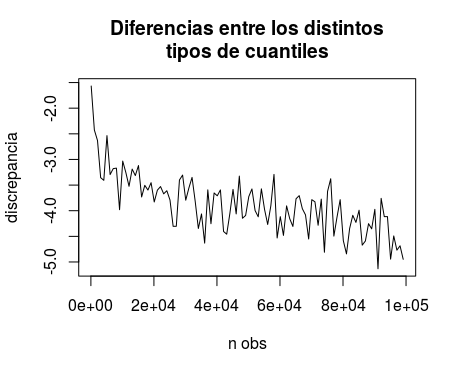
Imagino que crecerán, por otro lado, con la dispersión de los datos implicados alrededor del cuantil de interés.
Atribución: me puso sobre la pista de esta peculiaridad de quantile esto.