Este mes de julio, cuórum mediante, impartiré en la UPC un curso que he maltitulado, mor de brevedad, Estadística Bayesiana Aplicada.
Los cursos de estadística bayesiana son teoría, mucha teoría, y unos ejemplos tontos que quieren justificarla. Del tipo: hagamos lo que ya sabemos hacer de otra manera más; busquemos una alternativa molona al p-valor (y usémosla como usar íamos un p-valor, por supuesto), etc.
Mi curso debería haberse titulado algo así como: Problemas reales (aunque simplificados por motivos estrictamente pedagógicos) resueltos con tecnología bayesiana porque, si no, dígame Vd. cómo lo haría: ¿con optim? Jajajajaja…
Es un curso en el que aplicaciones reales justifican la tecnología y esta, a su vez, la teoría. Y sí, enlazará con teoría de la decisión propiamente formulada, remitirá (a lo más) a libracos, y enseñará a resolver los problemas con Stan.
Uno de los problemas avanzados pero a la mano que quiero plantear es el del kriging. Por simplificar, en una dimensión. Hay muchas cosas de contar eso del kriging, muchas de las cuales no he entendido jamás, pero la más sencilla es generalizando los modelos lineales generalizados. Por simplificar, desgeneralicemos los GLMs y partamos del modelo lineal,
$$ Y_i | X_i ,, \sim ,, N(\mu_i, \sigma)$$
o bien,
$$ y_i = \mu(x_i) + \epsilon$$
donde $\epsilon$ se ajusta a la especificaión previa. Si conocemos $\mu$, podremos hacer predicciones para nuevos valores $x$.
Aquí las observaciones son independientes. Pero en nuestro problema observamos medidas en determinados puntos (en un terreno (2D), en una línea (1D), etc.) y sabemos que existe cierta regularidad: los puntos próximos están correlacionados entre sí.
El objetivo del kriging es poder realizar estimaciones en puntos no observados utilizando no solo nuestro conocimiento de $\mu$, sino también aquello que nos aporten los puntos $x$ conocidos próximos al que nos interesa.
Por concretar, dados los valores
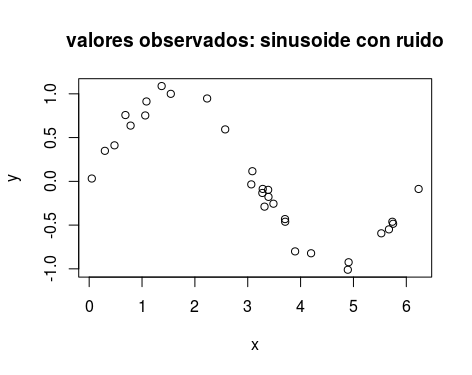
podríamos querer obtener estimaciones de la función subyacente en alguno intermedio. O en una rejilla determinada. Sí, como si usásemos loess o similar. Pero, en nuestro caso, usando el siguiente modelo:
$Y | X ,, \sim ,, N(\mu, \Sigma)$
donde $\mu$ es un vector de medias y $\Sigma$ es una matriz de covarianzas en la que $\Sigma_{ij}$ es una función decreciente de la distancia entre $x_i$ y $x_j$.
Al modelo básico se le pueden añadir cascabeles variados:
- Sumarle a $\Sigma$ una matriz diagonal que recoja el error de medición.
- Variables independientes y sus coeficientes en la determinación de la media $\mu$.
- Funciones de enlace para que $Y$ sea no el valor deseado sino $\log(\lambda)$ en un modelo de Poisson o la invlogis de una probabilidad.
En nuestro caso, se puede estimar la función subyacente en una rejilla,
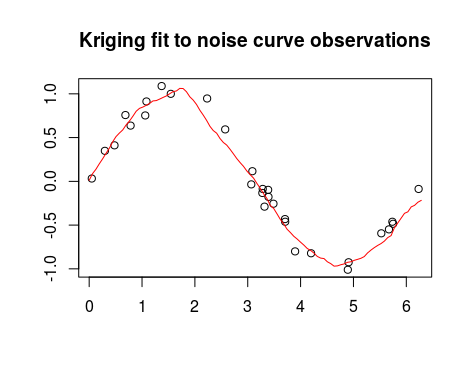
con el código
library(rstan)
library(reshape2)
library(ggplot2)
library(plyr)
n_sample <- 30
n_grid <- 100
sd_error <- 0.1
x <- sort(runif(n_sample) * 2 * pi)
y <- sin(x) + rnorm(n_sample, 0, sd_error)
rejilla <- seq(0, 2 * pi, length.out = n_grid)
all_x <- c(x, rejilla)
distances <- as.matrix(dist(as.matrix(all_x), method = "manhattan"))
distances <- distances^1.5
stan_data <- list(
N1 = n_sample,
N2 = n_grid,
N = n_sample + n_grid,
x = all_x,
y0 = y,
dists = distances
)
fit_alt <- stan(file = "krigging_1D.stan",
data = stan_data,
iter = 10000, warmup = 5000,
chains = 1, thin = 10)
res <- as.data.frame(fit_alt)
preds <- res[, grep("^y2", colnames(res))]
preds$id <- 1:nrow(preds)
preds <- melt(preds, id.vars = "id")
preds$x <- gsub("y2\\[(.*)\\]", "\\1", preds$variable)
preds$x <- as.numeric(preds$x)
preds$x <- rejilla[preds$x]
ggplot(preds, aes(x = x, y = value)) + geom_point(alpha = 0.1)
tmp <- ddply(preds, .(x), summarize, y = median(value))
plot(x, y, main = "Kriging fit to noise curve observations",
xlab = "", ylab = "")
lines(tmp$x, tmp$y, type = "l", col = "red")que tira de
data {
int<lower=1> N1; // number of data points
int<lower=1> N2; // number of grid points
int<lower=1> N; // N1 + N2
real x[N]; // number of outcomes
real y0[N1]; // observed values
matrix[N, N] dists; // distances between points
}
parameters {
vector[N2] y2; // predictions for missing values (grid)
real <lower = 0> sigma;
real <lower = 0> phi;
real <lower = 0> sd_noise;
real mu;
}
model {
vector[N] y;
vector[N] means;
matrix[N,N] Sigma;
matrix[N,N] L;
// y values
for(i in 1:N1) y[i] = y0[i];
for(i in 1:N2) y[N1+i] = y2[i];
// means: equal to mu
for(i in 1:N) means[i] = mu;
// priors (non informative)
sd_noise ~ normal(0, 1);
sigma ~ normal(0, 1);
phi ~ normal(0, 3);
mu ~ normal(0, 1);
y2 ~ normal(0, 1);
// covariance matrix
Sigma = sigma^2 * exp(-phi * dists);
for(i in 1:N) Sigma[i,i] = Sigma[i,i] + sd_noise;
// model
L = cholesky_decompose(Sigma);
y ~ multi_normal_cholesky(means, L);
}En el código anterior $\Sigma$ es una matriz que tiene valores $\sigma^2 + r^2$ en la diagonal ($r$ es la desviación estándar del ruido de observación) y $\sigma^2 \exp(-\phi d_{ij}^{1.5})$ fuera de ella.
Así que, en resumen, el kriging es conceptualmente sencillo y computacionalmente asequible. Y si te interesan estas y más cosas y a primeros de julio estás por Barcelona con tu portátil, planteáte aprender y practicar estas cosas por las mañanicas de una semana.