Me he enterado por esto de una noticia que recoge, por ejemplo, Europa Press, y de donde extraigo un párrafo que lo dice casi todo:
El secretario de Estado de Sanidad, Javier Padilla, ha advertido este miércoles que el número de personas que consumen alcohol a diario en la Comunidad de Madrid “casi se ha duplicado” desde el año 2000, mientras que en el conjunto de España aumenta “de forma muy pequeña”, y ha acusado a la presidenta regional…
Me ha llamado bastante la atención: generalmente, las cifras macro guardan una correspondencia con lo que uno observa en su entorno micro mientras que en este caso ocurre lo contrario. Esa discrepancia puede significar muchas cosas, por supuesto. Así que he invertido un poco de tiempo en tratar de averiguar qué puede estar pasando.
El Observatorio Español de las Drogas y las Adicciones, adscrito al Ministerio de Sanidad, publica cada dos años una monografía sobre el uso de alcohol. En la de 2024 no se aprecia ningún patrón de consumo excesivo de alcohol en Madrid: de hecho, está por debajo de la media nacional en casi todas las métricas. Ni la nota de prensa ni el resumen ejecutivo de ese estudio mencionan a la Comunidad de Madrid explícitamente.
Ese informe se nutre fundamentalmente de los datos de la EDADES (Encuesta sobre alcohol y otras drogas en España), del Ministerio de Sanidad. En el informe correspondiente a la edición de 2024 de dicha encuesta, la palabra “Madrid” aparece 17 veces y en ninguna de ellas se hace referencia a excesos de consumo de alcohol o incrementos del mismo.
En ninguno de los dos informes anteriores se desglosa el consumo de alcohol diario por CCAA o su evolución temporal. Sin embargo, otras medidas menos específicas apuntan a un descenso paulatino en el consumo de alcohol tanto en Madrid como en el conjunto de España.
Existe sin embargo un informe de la Comunidad de Madrid, el Informe de avance de resultados principales de la encuesta EDADES 2024, donde aparece la gráfica
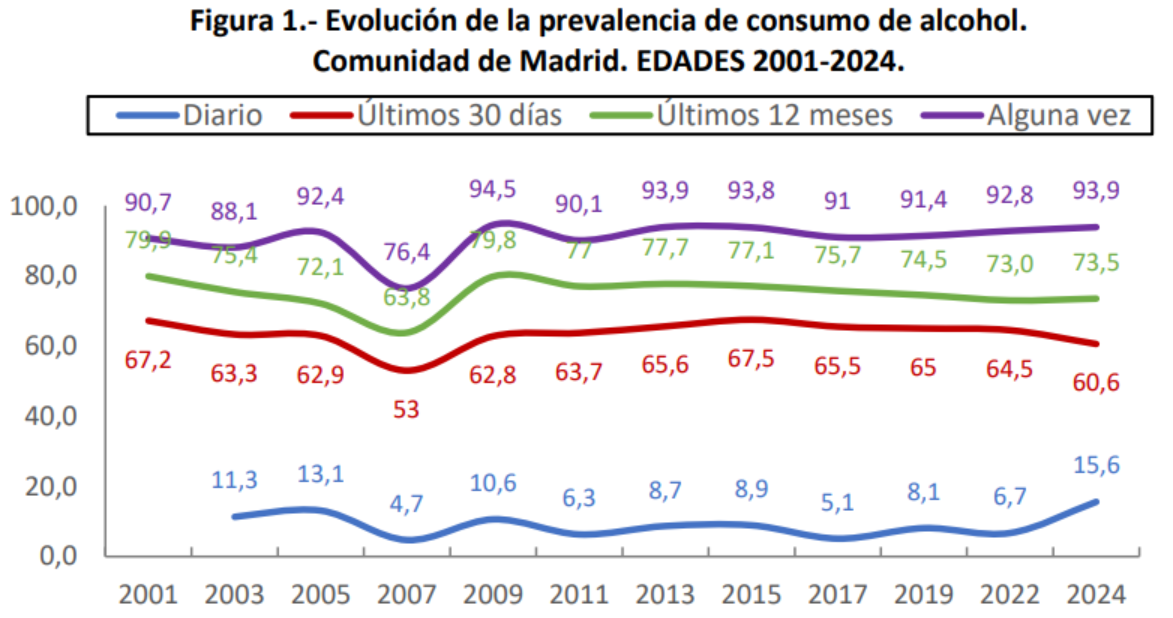
sobre la que sus autores comentan escuetamente —mucho más de lo que se espera de gente que tiene estudios y que ha aprobado una oposición—:
El indicador de consumo diario es el que muestra un mayor incremento (15,6% vs. 6,7%, más del doble de incremento), seguido del consumo de alguna vez en la vida (93,9% vs. 92,8% respectivamente) y del consumo en los últimos 12 meses (73,5% vs. 73,0%) (figura 1).
Pero eso no es realmente lo que dice el gráfico (y los datos subyacentes). Lo que el gráfico dice realmente es que la encuesta está mal hecha. Por ejemplo, es materialmente imposible que el consumo de alcohol “alguna vez en la vida” oscile como lo hizo en 2007. Tendrías que haber deportado fuera de la provincia a prácticamente un millón de madrileños que alguna vez han probado el alcohol, reemplazarlos por un millón de abstemios, hacer la encuesta y volver luego a dejar las cosas tal como estaban para lograr una fluctuación de esa magnitud.
El problema, como tantas veces, no está en el territorio sino en el mapa.
Si se hacen encuestas sobre indicadores que tienen que ver con personas, es porque existe inercia en el comportamiento humano. Eso se sabe desde siempre, pero especialísimamente, de Durkheim para acá. Lo que pasa esta semana se parece mucho a lo que pasó la anterior: el que bebía sigue bebiendo, el que creía que la tierra era plana lo sigue creyendo; hay más o menos el mismo número de suicidios, nacimientos y divorcios, etc. Los indicadores que tienen que ver con humanos varían despacio. De hecho, para cambiarlos, la gente gasta fortunas en sicólogos, siquiatras, Ozempic, antidepresivos, etc., y ni con esas. Asì que si alguien pretende hacerte creer que el porcentaje de quienes beben todos los días en Madrid oscila como la curva azul del gráfico anterior, hay motivos para pensar que esa persona es, precisamente, uno de los más contumaces consumidores de etanol.
Los autores del informe deberían haber explicitado sus reservas hacia los resultados en el texto. Son funcionarios y no personal eventual precisamente para eso, para poder hacer valer ese buen criterio que les reconoció el BOE y por el que adquirieron su plaza (algo me estaba chirriando por dentro según escribía esas tres últimas palabras) sin consideraciones estratégicas ulteriores. Pero tampoco vamos a sorprendernos de que las cosas sean de esta manera a estas alturas de partido.
Coda técnica
Si damos por buena una proporción $p = .1$, con una muestra del orden de 2000 entrevistados, la desviación estándar del estimador de $p$ debería ser del orden de
$$\sqrt{\frac{p(1-p)}{2000}} = 0.0067$$
o un 0.6%. Así que, suponiendo un $p$ que varía muy lentamente a lo largo del tiempo, las variaciones típicas (con 95% de probabilidad) deberían ser inferiores al 1.2% entre ediciones. Cosa que no ocurre por motivos que los informes no se detienen en explicar, dando por bueno ese principio espurio de la estadística pública: un fenómeno $X$ es precisamente y no otra cosa que aquello que resulta del procedimiento diseñado para medirlo.
Coda tecno-pragmática
La anterior es una coda teórica, de libro. Los libros de muestreo hablan de poblaciones sin distingos entre las que son de urnas, relojes, insectos o fulanos. Pero para que apliquen los principios de la coda anterior tienen que regir una serie de condiciones ceteris paribus estrictas y que, casi seguro, no se dan en las encuestas que se discuten más arriba. La serie de encuestas podrá detectar grandes variaciones diacrónicas de comportamiento en la población de interés; pero, con casi total seguridad, las fluctuaciones restantes son artefactos del instrumento de medición.