Si se puede hacer para Japón, también se puede hacer para España:
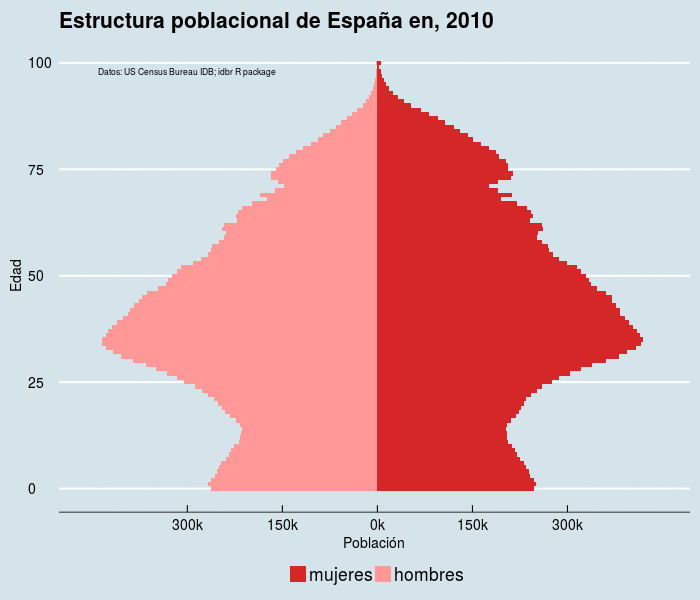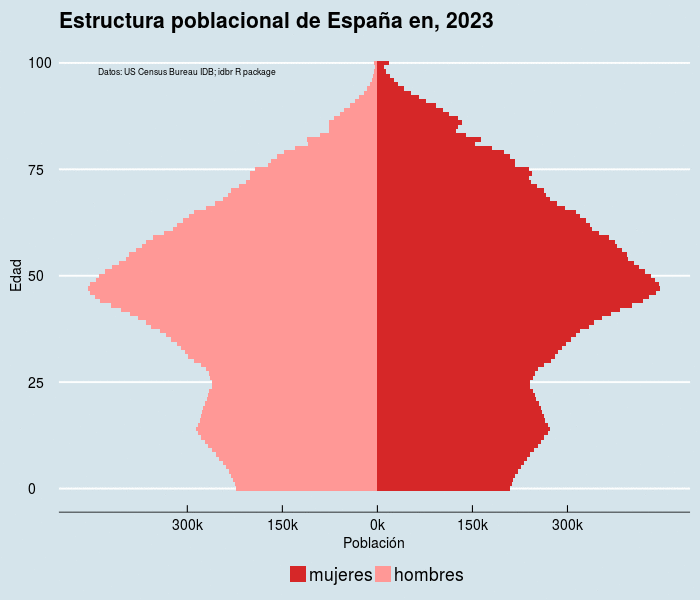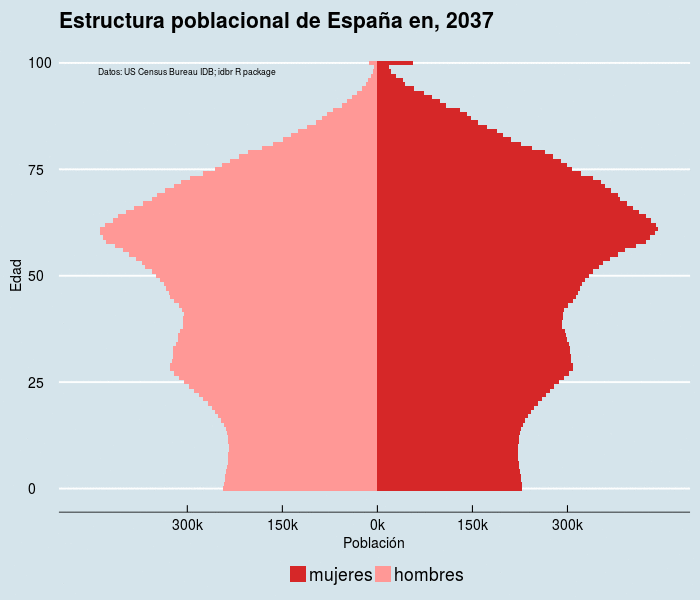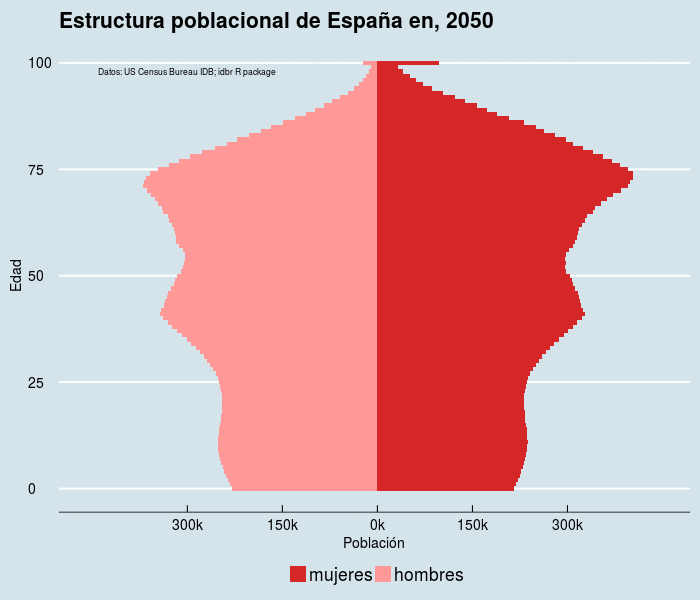
El código,
library(idbr)
library(ggplot2)
library(animation)
library(ggthemes)
idb_api_key("pídela en https://www.census.gov/data/developers/data-sets/international-database.html")
male <- idb1('SP', 2010:2050, sex = 'male')
male$SEX <- "hombres"
male$POP <- -male$POP
female <- idb1('SP', 2010:2050, sex = 'female')
female$SEX <- "mujeres"
spain <- rbind(male, female)
saveGIF({
for (i in 2010:2050) {
title <- as.character(i)
year_data <- spain[spain$time == i, ]
g1 <- ggplot(year_data, aes(x = AGE, y = POP, fill = SEX, width = 1)) +
coord_fixed() +
coord_flip() +
annotate('text', x = 98, y = -300000,
label = 'Datos: US Census Bureau IDB; idbr R package', size = 3) +
geom_bar(data = subset(year_data, SEX == "mujeres"), stat = "identity") +
geom_bar(data = subset(year_data, SEX == "hombres"), stat = "identity") +
scale_y_continuous(breaks = seq(-300000, 300000, 150000),
labels = paste0(as.character(c(seq(300, 0, -150), c(150, 300))), "k"),
limits = c(min(spain$POP), max(spain$POP))) +
theme_economist(base_size = 14) +
scale_fill_manual(values = c('#ff9896', '#d62728')) +
ggtitle(paste0('Estructura poblacional de España en, ', title)) +
ylab('Población') +
xlab('Edad') +
theme(legend.position = "bottom", legend.title = element_blank()) +
guides(fill = guide_legend(reverse = TRUE))
print(g1)
}
}, movie.name = 'spain_pyramid.gif', interval = 0.1,
ani.width = 700, ani.height = 600)



