¿Eres un buen "científico de datos"?
Entonces sabrás responder a muchas de estas preguntas.
Entonces sabrás responder a muchas de estas preguntas.
En serio, aviso: aprenderéis tanto como desaprenderéis si leéis esto.
Por si no os habéis atrevido, os lo resumo. El autor de la cosa ha construido configuraciones de puntos tales como

y ha creado conjuntos de datos de distinto número de registros con esa distribución de colores. Luego ha puesto varios modelos de clasificación habituales a tratar aprenderla. Y ha obtenido patrones tales como

Uno puede entretenerse mirando qué modelos ajustan mejor y peor en función del tipo original de configuración, del modelo, del tamaño de la muestra, etc. y, de esa manera, ir construyendo subrepticiamente unas preferencias subconscientes sobre el conjunto de técnicas existentes para solucionar problemas de clasificación binaria.
Te encargan un modelo. Por ejemplo, relacionado con el uso de tarjetas de débito y crédito (aunque a lo que me referiré ocurre en mil otros contextos). Una variable que consideras importante es la proporción de veces que se usa para sacar dinero de cajeros (y no para pagar en establecimientos). Así que, para cada cliente, divides el número de retiradas por el número de veces que la tarjeta se ha usado y obtienes ese número entre el 0 y el 1 (o entre el 0% y el 100%).
Hija de la improvisación de hace un ratico, habrá mañana sábado día 4 (de octubre de 2014), a las 19:00 una reunión de gente poco cabal en MartinaCocina para discutir asuntos relacionados con el análisis de textos (y en una vertiente más lúdica, la generación de textos) usando cadenas de Markov.
Nos juntaremos, entre otros, los autores del Escritor Exemplar (uno de los cuales es quien suscribe) y el de Markov Desencadenado.

Leí esto el otro día. Lo voy a replicar con mis datos.
Contexto
Google guarda datos de tus ubicaciones: tu tableta, tu ordenador, tu teléfono Android son espías a su servicio. Los datos los guarda en aquí (creo que necesitarás que en tu navegador haya una sesión abierta con tus credenciales del universo Google). Pulsando en administrar archivos y luego en crear archivos puedes seleccionar el tipo de información sobre ti que posee Google y que quieres descargarte. Para este ejemplo, será el Historial de Ubicaciones.
Trataré de usar pocas hoy. El otro día vi
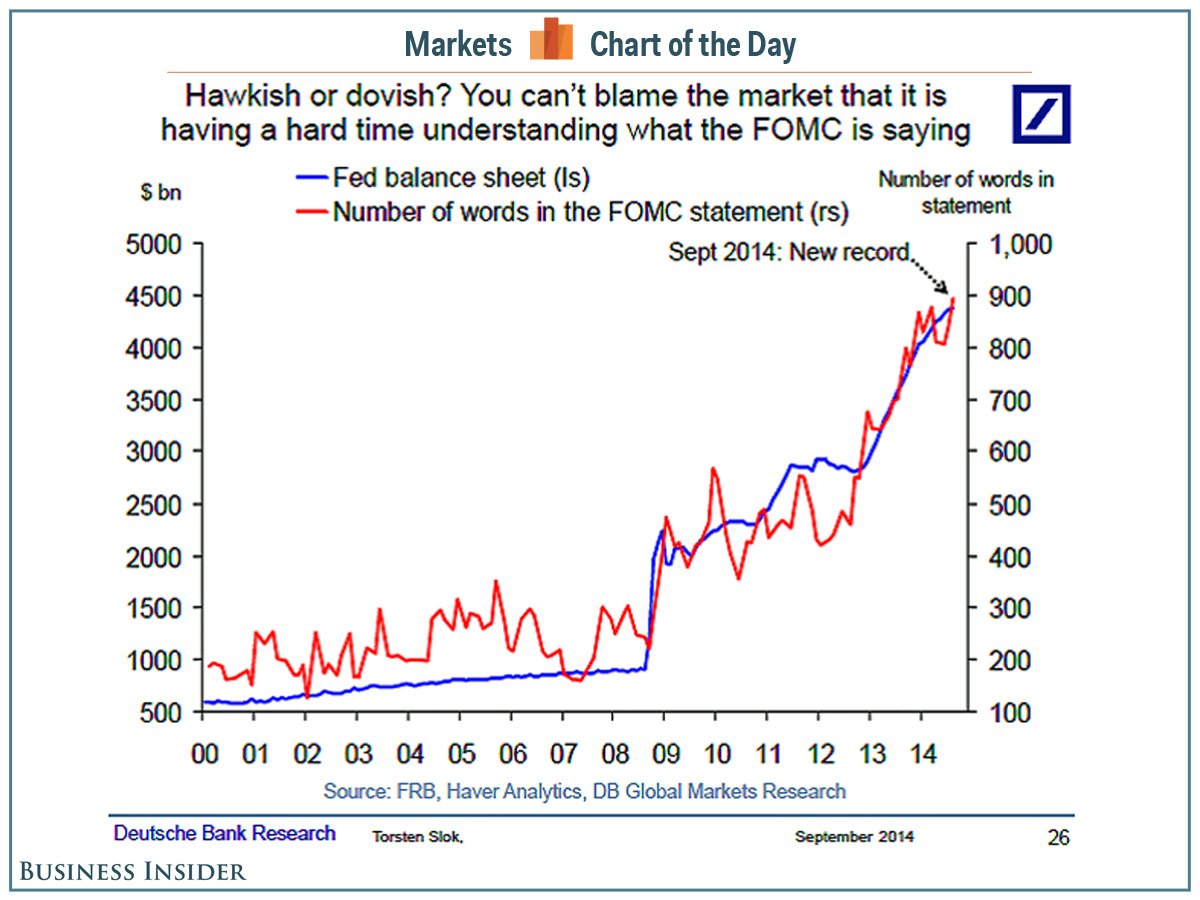
aquí. Me recordó que uno de mis proyectos abandonados sine die es el de estimar la rentabilidad real de productos financieros en función del número de palabras en sus correspondientes folletos.
Nota: curioso el gráfico anterior. Una de las variables es un stock y la otra es un flujo.
Otra nota: ahora que veo el gráfico me acuerdo de esto. Superpones dos funciones más o menos monótonas en una gráfica de doble escala y ya tienes la entrada/artículo del día.
Me gusta criticar. Bien lo saben quienes me siguen. Pero hoy toca aplaudir un artículo tan raro como valiente. Que no hace sino criticar por mí. Se titula On the Near Impossibility of Measuring the Returns to Advertising. Sus autores, quiero subrayarlo aquí, trabajan en Google y Microsoft.
Los métodos data driven gozan del mayor de los predicamentos. Véase una pequeña muestra extraída de una reciente conversación en Twitter:

Hoy he encontrado esto en Twitter:

Míralo bien. Vuelve a mirarlo. Efectivamente, los ricos votaron en contra de la independencia; los pobres, a favor. ¿Verdad?
Muchos, yo incluido, estamos inclinados a pensarlo así. Los resultados de una pequeña muestra que he hecho en la oficina han sido contundentes: todos, a pesar de sus doctorados, han estado de acuerdo unánimemente con el juicio anterior.
Así que ha sucedido lo siguiente:
Fui un pájaro mañanero con [plyr](http://cran.r-project.org/web/packages/plyr/index.html).
Probé una vez [data.table](http://cran.r-project.org/web/packages/data.table/index.html) y no me convenció. Volví a él cuando realmente lo necesitaba y ahora es la prolongación de mis dedos.
Aún no me he puesto con [dplyr](http://cran.r-project.org/web/packages/dplyr/index.html) aunque he visto el suficiente código escrito con él que no creo que me cueste mucho comenzar a usarlo.
Pero tengo la sensación de que tenemos un cisma como el de vi contra emacs en ciernes. Comienza a haber, parece, partidarios acérrimos de tirios y troyanos. Así que abro la sección de comentarios para que opines sobre estos paquetes. A mí y a muchos otros lectores nos gustaría conocer tu opinión al respecto. ¿Cuál utilizas? ¿Qué te gusta de cada cual? ¿Cuál recomendarías?
Voy a escribir sobre un artículo como no debe hacerse: sin haberlo leído. Los bayesianos dirían que esta opinión que aquí voy a vertir es mi prior para cuando encuentre el tiempo y bajo la cual matizaré lo que en el se diga. Lo advierto, en todo caso, para que quien me lea no renuncie al sanísimo escepticismo.
Voy a hablar de Inferring causal impact using Bayesian structural time-series models y del paquete de R que lo acompaña, CausalImpact, cuyos autores trabajan en Google.
