Los datos están histogramizados... ¿quién los deshisotogramizará?
Hace un tiempo quise hacer cosas malísimas con datos fiscales de España y Dinamarca. Pero los datos estaban histogramizados:
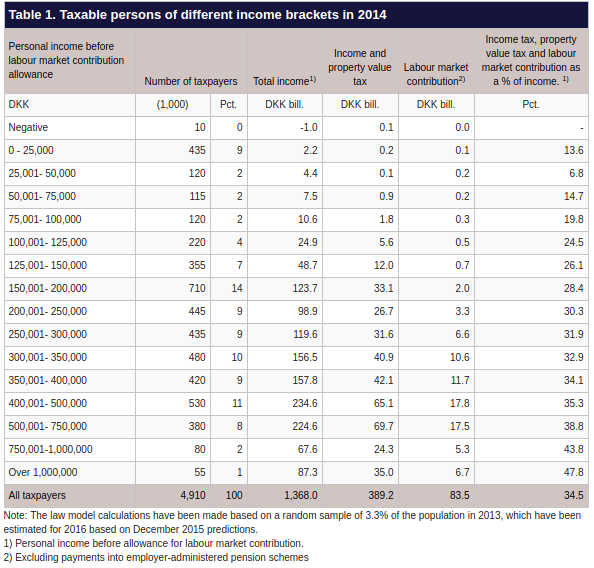
Gracias a Freakonometrics di con binequality. Adaptando su código, escribo
library(rvest)
library(plyr)
dk <- read_html("http://www.skm.dk/english/facts-and-figures/progression-in-the-income-tax-system")
tmp <- html_nodes(dk, "table")
tmp <- html_table(tmp[[2]])
header <- tmp[1,]
tmp <- tmp[-c(1, 2),]
colnames(tmp) <- header
# elimino declaraciones negativas
tmp <- tmp[-1,]
# elimino el total
tmp <- tmp[-(nrow(tmp)),]
colnames(tmp) <- c("rango", "contribuyentes",
"X1", "income", "tax1", "tax2", "pct")
irpf_dk <- tmp[, c("rango", "contribuyentes",
"income", "tax1", "tax2")]
irpf_dk$contribuyentes <- as.numeric(irpf_dk$contribuyentes)
irpf_dk$income <- as.numeric(irpf_dk$income)
irpf_dk$tax1 <- as.numeric(irpf_dk$tax1)
irpf_dk$tax2 <- as.numeric(irpf_dk$tax2)
irpf_dk$tax <- irpf_dk$tax1 + irpf_dk$tax2
irpf_dk$tax1 <- irpf_dk$tax2 <- NULL
irpf_dk$pct <- irpf_dk$tax / irpf_dk$income
irpf_dk$desde <- c(0, 25, 50, 75, 100, 125, 150,
200, 250, 300, 350, 400, 500, 750, 1000)
irpf_dk$hasta <- c(irpf_dk$desde[-1], Inf)
irpf_dk$desde <- irpf_dk$desde / 7.44
irpf_dk$hasta <- irpf_dk$hasta / 7.44
irpf_dk$income <- irpf_dk$income / 7.44
irpf_dk$tax <- irpf_dk$tax / 7.44
irpf_dk$mean_income <- irpf_dk$income /
irpf_dk$contribuyentes * 1000
irpf_dk$rango <- NULLpara bajar y preprocesar los datos y después

