Inspirado en esto construí
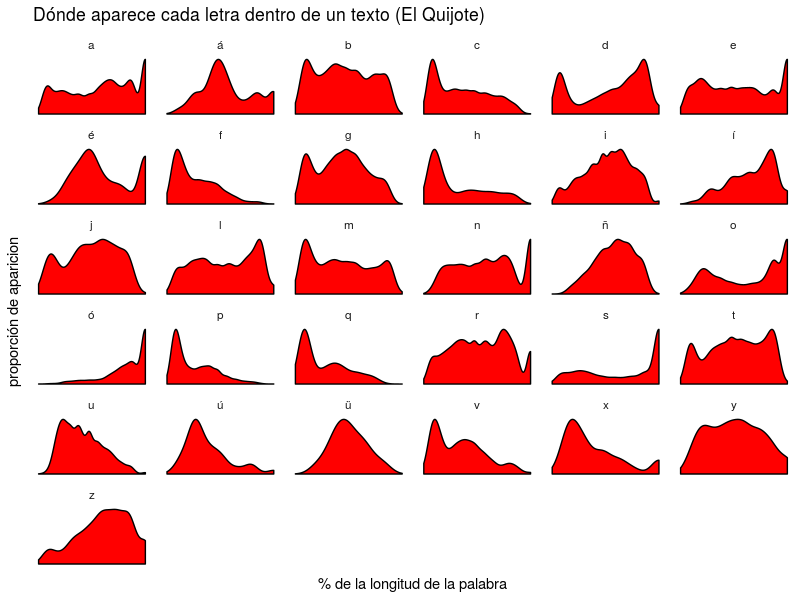
usando como texto el Quijote y como código una versión mucho más simple y limpia que (aunque inspirado en) la del enlace original:
library(stringr)
library(plyr)
library(ggplot2)
raw <- readLines("http://www.gutenberg.org/cache/epub/2000/pg2000.txt")
# limpieza de encabezamientos
textfile <- raw[-(1:36)]
textfile <- text[1:which(text == "Fin")]
# en una única cadena
textfile <- paste(textfile, collapse= " ")
# limpieza
textfile <- str_to_lower(textfile)
textfile <- str_replace_all(textfile, "[[:punct:]]|[[:digit:]]", " ")
# selección de palabras
words <- unique(unlist(str_split(textfile, " ")))
words <- words[words != ""]
# recolección de estadísticas
res <- ldply(words, function(word){
tmp <- str_split(word, "")[[1]]
data.frame(word = word,
letra = tmp,
posicion = 1:length(tmp) / length(tmp),
stringsAsFactors = FALSE)
})
tmp <- table(res$letra)
tmp <- names(tmp[tmp > 10])
res <- res[res$letra %in% tmp,]
ggplot(res, aes(x = posicion)) +
geom_density(fill = "red") +
facet_wrap( ~ letra, scales = "free_y") +
ggtitle("Dónde aparece cada letra dentro de un texto (El Quijote)") +
ylab("proporción de aparicion") + xlab("% de la longitud de la palabra") +
scale_fill_brewer(palette = "Set1") + theme_minimal() +
theme(axis.ticks = element_blank(),
axis.text.y = element_blank(),
axis.text.x = element_blank(),
legend.position = "none",
panel.grid.major = element_blank(),
panel.grid.minor = element_blank())