Esta es una cosa bastante contraintituiva. Uno diría que en la moda, pero no es exactamente así.
Veamos qué pasa con la distribución normal conforme aumenta la dimensión.
En una dimensión son más frecuentes los valores próximos al centro:
hist(abs(rnorm(10000)), breaks = 100,
main = "distribución de la distancia al centro")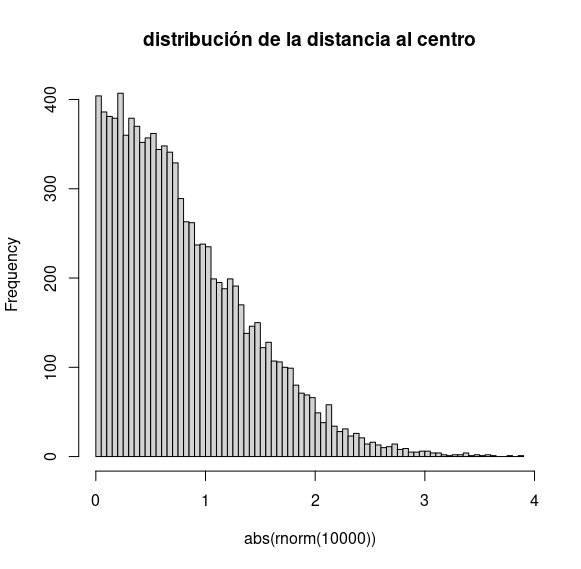
Pero en dimensiones más altas (p.e., 10), la cosa cambia:
library(mvtnorm)
muestra <- rmvnorm(10000, rep(0, 10),
diag(rep(1, 10)))
distancias <- apply(muestra, 1,
function(x) sqrt(sum(x^2)))
hist(distancias, breaks = 100,
main = "distribución de la distancia al centro")
Lo más frecuente es obtener observaciones ya no próximas al centro sino en un anillo alrededor de él y a cierta distancia del mismo. El centro sigue siendo el punto más probable, la moda, pero es demasiado chiquito para contener un porcentaje significativo de la muestra. Muy lejos, hay mucho espacio; pero tiene una probabilidad ínfima. El grueso de las observaciones hay que buscarlo en un anillo alrededor del centro.
El por qué esto es relevante (y dónde), así como mucha más información (muy sesuda) al respecto, está a un enlace de los interesados.