Uno de los metaprincipios de la construcción de modelos estadísticos es que la calidad de los modelos es función de la cantidad de información que hay en los datos de entrenamiento. No existe el bootstrap en el sentido etimológico del término: no puede uno levantarse en el aire tirando hacia arriba de los cordones de los zapatos. Pero al hilo de una noticia reciente, Gelman discute si añadir ruido a los datos permite reducir el sobreajuste. Además, en la discusión al respecto, alguien cita el artículo de 1995 Training with Noise is Equivalent to Tikhonov Regularization, una especie de penalización en el tamaño de los coeficientes al modo de la regresión ridge.
Un artículo de Asterisk discute los problemas existentes en muchos países para elaborar censos de población fiables. Otro más en la serie acerca de la decreciente calidad de las estadísticas públicas. Aunque en este caso afecte principalmente a países muy perfectibles.
La falacia NAXALT:
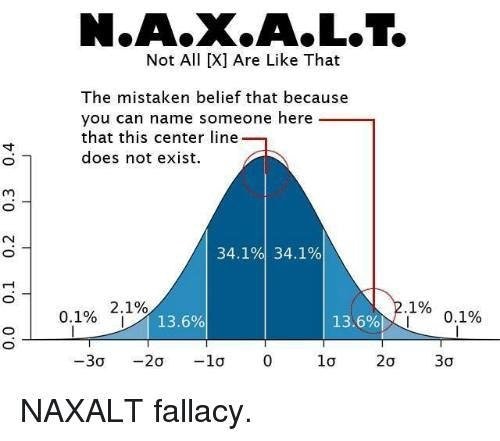
Realmente no tiene tanto que ver con la estadística como con la epistemología (torcida de tanta gente), pero…
La figura
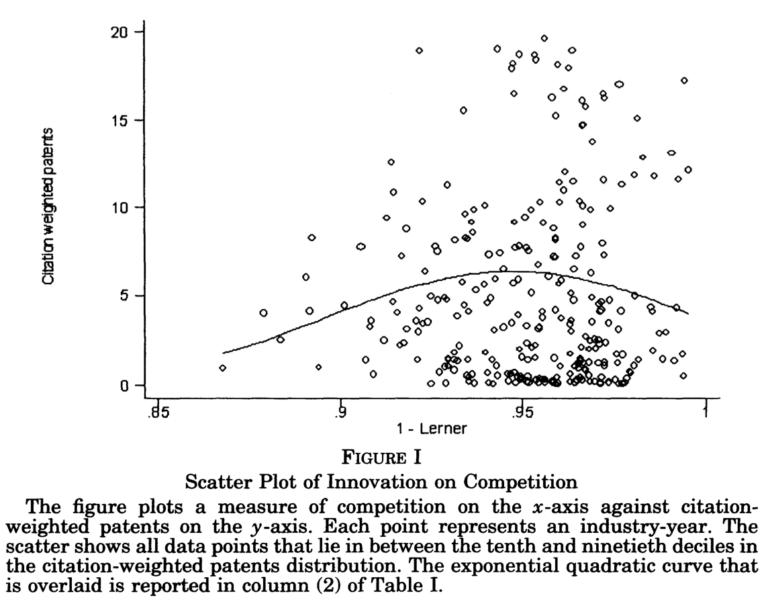
está extraída de un artículo convenientemente titulado Competition and Innovation: An Inverted-U Relationship coescrito por uno de los últimos agraciados por el premio Nobel. Aquí y, especialmente, aquí, se abunda sobre el asunto.
A una entrada de ya hace bastante tiempo de Gelman, No vehicles in the park, se le puede sacar punta de muchas maneras. Por un lado, Gelman realiza un análisis completo de unos datos que, aparte de curiosos por su misma naturaleza, tienen algunas peculiaridades estadísticas interesantes. Luego, el texto detalla todas las idas y venidas estadísticas, todos los trucos que Gelman va incorporando a su análisis, todas las resistencias que estos le ofrecen y todas las contramedidas que toma para irlas solventando. Finalmente, produce cierto desasosiego: parte de los problemas a los que se enfrenta tienen un origen y una solución enteramente extraestadística y, hasta cierto punto, computacional. Nos recuerda cómo podemos estar haciendo todo correctamente desde el punto de vista estadístico y, aun así, metiendo la pata por una minucia sintáctica. Bueno, realmente no es tal minucia: apunta a un problema que ocurre con cierta frecuencia y que no debería sorprender demasiado a quienes tienen experiencia en esos asuntos. Pero que nos invita a recordar que las herramientas estadísticas actuales no nos permiten desacoplarnos del nivel computacional inmediatamente inferior (como tal vez la medicina no puede desacoplarse de la biología y esta, a su vez, de la química).
Algún día tengo que sacar tiempo para estudiar las posibles aplicaciones de los artículos mencionados en Two New Preprints on Multilevel Hidden Markov Models en las cosas que hago hoy en día.
Escribe Frank Harrell, en su libro Regression Modeling Strategies:
Las relaciones entre las variables casi nunca son lineales […]. Muchos de los que no han estudiado en profundidad los problemas del sesgo y la eficiencia creen que la presencia de relaciones no lineales se remedia tramificando las variables continuas en intervalos. Es lo más desastroso que pudiere hacerse.
Finalmente, unas cuantas notas sobre estadística bayesiana:
- 7 reasons to use Bayesian inference!, algunas de las cuales no son las habituales, como la posibilidad de ajustar modelos mucho más sofisticados de los que permite la estadística frecuentista de manera natural.
- Bayesian Thinking contiene las diapositivas de una charla de Frank Harrell sobre (las partes más relevantes de) la historia y los fundamentos de la estadística bayesiana.
- It’s a JAX, JAX, JAX, JAX World trata sobre cómo construir lenguajes probabilísticos sobre plataformas que no sean JAX es nadar contracorriente. NumPyro se va a comer a Stan irremisiblemente.