Busco viñetista (para MicroDatosEs)
Las viñetas son complementos importantes para un paquete, para que un usuario circunstancial pruebe y use un paquete. Uno de los míos, MicroDatosEs carece de ellas.
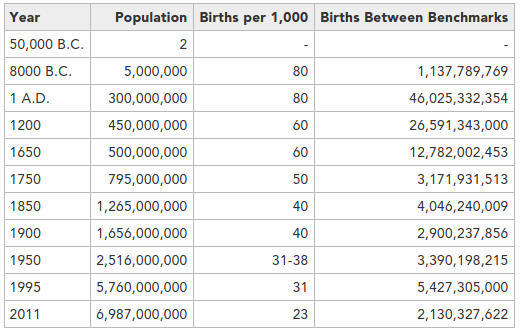
Me gustaría poder añadirle una o más que ilustraran cómo usarlo. Por ejemplo, para reproducir algunos de los números que ofrece el INE en sus notas de prensa.
Por eso te ofrezco la posibilidad de que te conviertas en viñetista. Eso te convertiría en colaborador del paquete (que es algo que cabe en un currículo). Eso sí, no subiría cualquier cosa.