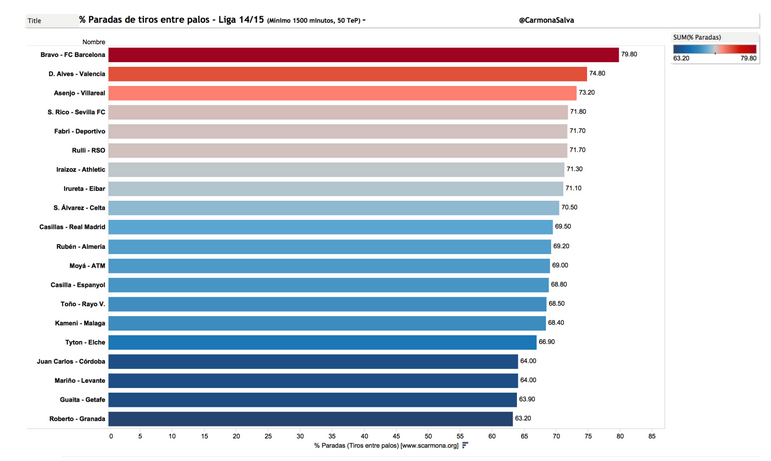
Misma p, distinto n, luego...
Tres situaciones. La primera:
n <- 20
y <- 15
test <- prop.test(y, n, p = .5)
test$p.value
# [1] 0.04417134
test$conf.int
# 0.5058845 0.9040674La segunda:
n <- 200
y <- 115
test <- prop.test(y, n, p = 0.5)
test$p.value
#[1] 0.04030497
test$conf.int
# 0.5032062 0.6438648Y la tercera:
n <- 2000
y <- 1046
test <- prop.test(y, n, p = 0.5)
test$p.value
#[1] 0.0418688
test$conf.int
# 0.5008370 0.5450738En resumen:
- mismo problema
- distintos tamaños muestrales
- mismo p-valor (aproximadamente)
- distintos estimadores
- distintos intervalos de confianza
La pregunta: ¿qué circunstancia es más favorable? Una respuesta, aquí.