Esta entrada es casi una referencia para mí. Cada vez tiro más de lme4 en mis modelos y en uno en concreto que tengo entre manos toca simular escenarios. Para lo cual, simulate.merMod.
Véamoslo en funcionamiento. Primero, datos (ANOVA-style) y el modelo que piden a gritos:
library(plyr)
library(lme4)
a <- c(0,0,0, -1, -1, 1, 1, -2, 2)
factors <- letters[1:length(a)]
datos <- ldply(1:100, function(i){
data.frame(x = factors, y = a + rnorm(length(a)))
})
modelo <- lmer(y ~ (1 | x), data = datos)El resumen del modelo está niquelado:
summary(modelo)
# Linear mixed model fit by REML ['lmerMod']
# Formula: y ~ (1 | x)
# Data: datos
#
# REML criterion at convergence: 2560.3
#
# Scaled residuals:
# Min 1Q Median 3Q Max
# -3.6798 -0.6442 -0.0288 0.6446 3.3582
#
# Random effects:
# Groups Name Variance Std.Dev.
# x (Intercept) 1.5197 1.2328
# Residual 0.9582 0.9789
# Number of obs: 900, groups: x, 9
#
# Fixed effects:
# Estimate Std. Error t value
# (Intercept) -0.009334 0.412212 -0.023En particular,
- el término independiente es prácticamente cero;
- la desviación estándar de los residuos es casi uno (de acuerdo con el modelo de generación de datos);
- y la desviación estándar del efecto aleatorio de
xes, prácticamente,sd(a), como cabía esperar.
Ahora, la simulación. Así,
sims.u.false <- simulate(modelo, nsim = 1000, use.u = FALSE)
hist(apply(sims.u.false, 1, mean))obtengo
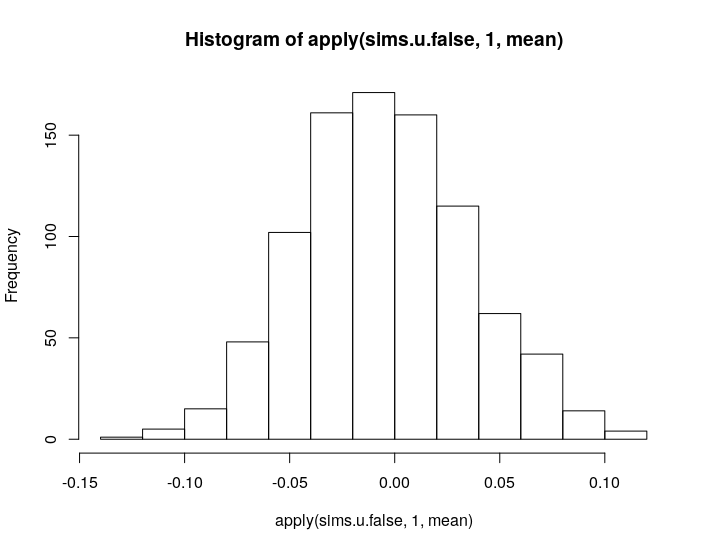
donde se ha ignorado el valor preespecificado de los efectos aleatorios (el valor de x) en los datos. En jerga estadística, es la predicción incondicional. Pero podemos exigir que se condicione en los valores de x (es decir, tener en cuenta de que hay observaciones con valores x predefinidos) así:
sims.u.true <- simulate(modelo, nsim = 1000, use.u = TRUE)
hist(apply(sims.u.true, 1, mean))para obtener
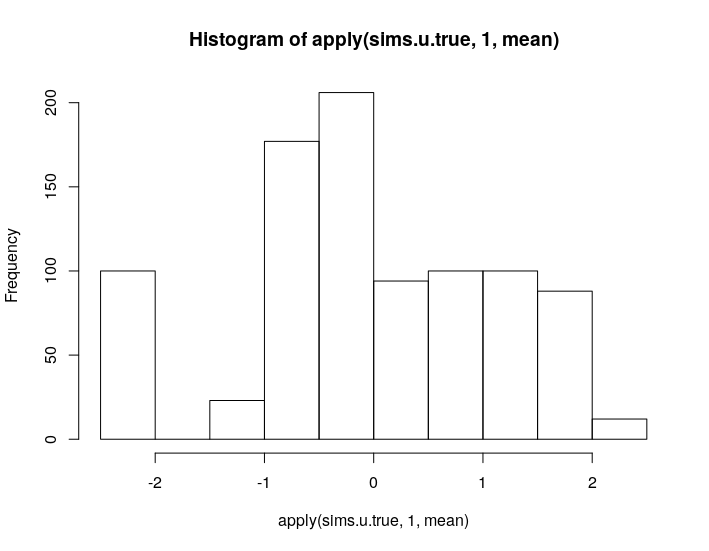
que tiene mucha mejor pinta. Nótese que en los datos originales hay sujetos cuyas predicciones tienen una media alrededor de 2 y que no se manifiestan en la simulación incondicional.
Finalmente, se pueden añadir observaciones con un nivel de x desconocido. La simulación condicional lo es para aquellas observaciones con niveles conocidos del factor aleatorio y, por decirlo de alguna manera, incondicional para las que no (y hay que usar la opción allow.new.levels = TRUE):
new_data <- data.frame(x = c(factors, "z"))
sims.u.true.alt <- simulate(modelo, nsim = 1000, use.u = TRUE, allow.new.levels = TRUE, newdata = new_data)
t(apply(sims.u.true.alt, 1, function(x) c(mean(x), sd(x))))
# [,1] [,2]
# 1 0.070687053 0.9992549
# 2 -0.004564873 0.9950122
# 3 -0.123329896 0.9882788
# 4 -0.808170380 1.0128760
# 5 -0.952436678 0.9484248
# 6 0.871509730 0.9727093
# 7 1.130616303 0.9958116
# 8 -2.098316767 0.9620356
# 9 1.926374151 0.9744446
# 10 0.012539384 1.0108651En particular, se aprecia cómo las simulaciones asociadas a la última observación, la que tiene el nivel desconocido de x z, están mucho más próximas a cero.
Autonota: Tengo que revisar por qué la varianza de esta última observación es similar a las que tienen el nivel conocido a. Deberían tener una varianza más grande, ¿no?