I.
A Treatise on Probability, la obra de Keynes (sí, el famoso) de 1921, es un libro muy extraño que se puede leer de muchas maneras. Puede servir, si se hace poco caritativamente, para denunciar el lastimoso estado en el que se encontraba la probabilidad antes de la axiomatización de Kolmogorov, 12 años después de su publicación. O también, si se hace más cuidadosamente, para rescatar una serie de consideraciones que aun hoy muchos hacen mal en ignorar.
Lo que no se le puede negar a Keynes es que fundamente todas las cuestiones que trata en casos y ejercicios prácticos que son tan actuales hoy como entonces. En algún punto del libro denuncia cómo muchos de los probabilistas que lo precedieron se restringieron a un conjunto muy concreto y simple de problemas en los que las cuestiones relativas a los fundamentos de la probabilidad son menos acuciantes, pero él no las rehuye y, en efecto, arranca una de las secciones más interesantes del libro con un [traduzco]:
Si pasamos de las opiniones de los teóricos a la experiencia de los hombres que la practican […]
II.
Esa sección pertenece al capítulo III en el que Keynes razona que las probabilidades no son (siempre) un número. No es ya solo que la probabilidad de un evento sea difícil de calcular o que nadie lo haya hecho, sino que, simplemente, en su parecer, no existe tal número. Y en particular, existen comparaciones imposibles. Para Keynes, de hecho, esos objetos que son las probabilidades forman parte de un conjunto dotado de un orden parcial, dentro del cual algunas comparaciones son posibles (p.e., admite que, con notación moderna, $P(A\cap B) \le P(A)$, pero no podemos aspirar a comparar las probabilidades de “el Real Madrid perderá 0-7 en su próximo partido” y “a Kennedy lo mataron los rusos”.
De hecho, una de las pocas ilustraciones del libro es
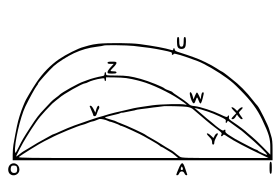
donde O es la imposibilidad, I es la certeza absoluta y los segmentos representan comparaciones posibles. Así, las probabilidades de A y V son comparables, pero no la de U y V.
III.
El capítulo VI, por otra parte, discute los llamados pesos de los argumentos y en él plantea la posibilidad y se inclina por sostener que la probabilidad es un objeto bidimensional, una especie de tupla, que agrupa la probabilidad en sí por una parte y el grado de certeza que tenemos de que ese valor sea el correcto. No sería entonces lo mismo (1/2, 4) que (1/2, 10): en el segundo caso representaría una situación en la que hemos acumulado mucha más evidencia acerca de la probabilidad del fenómeno.
IV.
Si tuviese una máquina del tiempo, entre otras muchas otras más cosas, por supuesto, la enfilaría hacia el Cambridge de 1920, buscaría al feliz de Keynes y le explicaría cómo, en el fondo, estas dos cuestiones que plantea —y que, como veremos, están aún vigentes y no siempre perfectamente resueltas— podrían solventarse de asumir que lo que él llama probabilidad y entiende como grado de creencia racional, no es otra cosa que una distribución en el intervalo [0, 1] (piénsese, por ejemplo, en la distribución beta).
Dos de tales distribuciones no son directamente comparables. De hecho, efectivamente, el conjunto de las distribuciones sobre [0, 1] forman un conjunto con un orden parcial —permítaseme no ser totalmente exacto en este punto y no proporcionar una definición de “<” satisfactoria— y que su dispersión podría representar ese grado de certeza en la asignación de la probabilidad que echa de menos en el capítulo VI.
[Nota: desgraciadamente, el mismo Keynes pide no confundir el grado de certeza en una probabilidad con el llamado error probable. El error probable es lo que en su época se usaba —en lugar de la desviación estándar, que acabó imponiéndose luego— para medir la dispersión de unos datos y no es otra cosa que el rango intercuartílico. Así que, en el fondo y desafortunadamente, está renegando de antemano a esa interpretación que hubiera querido haberle proporcionado.]
V.
Estas cuestiones que plantea Keynes no son especulativas: vienen motivadas por la práctica de la teoría de la probabilidad. Sus respuestas no son las que nos parecen hoy en día las correctas. Pero muchos siguen todavía o resolviéndolas incorrectamente o, lo que es aún más reprochable, ignorándolas.
Seguimos, por ejemplo, confiando ciegamente en los ránkings (véase esto, por ejemplo), ignorando intervalos de confianza (o credibilidad), haciendo exégesis del segundo decimal de una estimación del INE, etc.
¿Podría ser, planteo, porque ahora contamos con una teoría más asentada que nos hace avanzar en modo piloto automático desestimando consideraciones muy naturales que en otra época tal vez eran más conspicuas?