Toca TimesNet. Se trata de un modelo para la predicción (y más cosas: imputación, detección de outliers, etc.) en series temporales. Tiene que ser muy bueno porque los autores del artículo dicen nada menos que
As a key problem of time series analysis, temporal variation modeling has been well explored.
Many classical methods assume that the temporal variations follow the pre-defined patterns, such as ARIMA (Anderson & Kendall, 1976), Holt-Winter (Hyndman & Athanasopoulos, 2018) and Prophet (Taylor & Letham, 2018). However, the variations of real-world time series are usually too complex to be covered by pre-defined patterns, limiting the practical applicability of these classical methods.
Si alguien te dice que todo lo que sabes sobre series temporales tiene serias limitaciones para su implementación práctica y que tienen algo mejor, existe el imperativo epistemológico de averiguar de qué se trata. Lo que escribo a continuación resume mis esfuerzos por entenderlo.
I.
Imaginemos que nuestra serie temporal es un seno (de periodo 1000) como
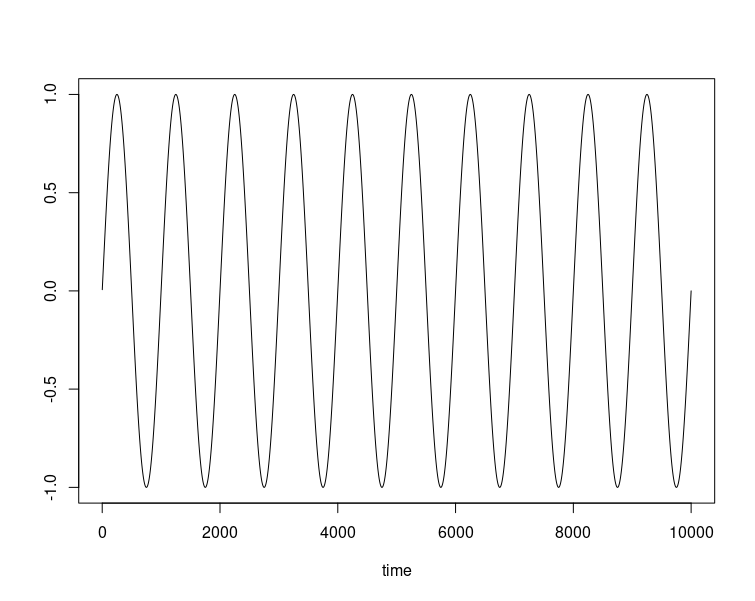
Entonces, TimesNet detecta —luego se verá cómo— que tiene tal periodo y la convierte en una matriz con 1000 filas (y, en este caso, 10 columnas). Podemos, además, ver esa matriz como una foto:

(Nota: en realidad, la foto debería ser $1000 \times 10$; por motivos estéticos, se muestra redimensionada.)
Esta foto se procesa usando lo que llaman parameter-efficient inception block y que creo que se refiere a la red neuronal con la estructura
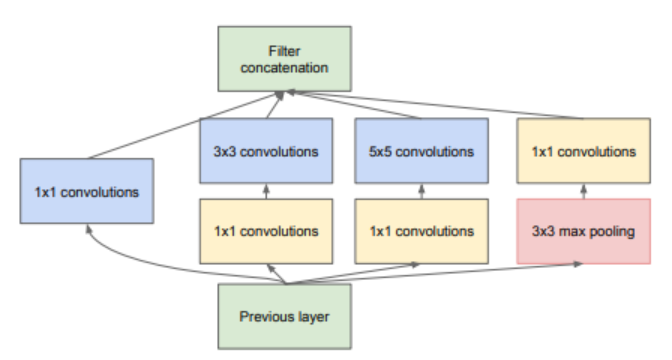
introducida en este artículo famoso de 2015. Este bloque mapea fotos en fotos (posiblemente, más simples). A partir de la foto transformada, uno puede volver a estirar los píxels para reconstruir una serie temporal de la misma longitud que la de entrada.
II.
¿Y, si como cabe esperar, nuestra serie temporal no es un seno? Entonces:
- Se hace la FFT de la serie temporal original.
- Se identifican las frecuencias más importantes.
- Se realiza el proceso descrito en el bloque anterior para cada una de las frecuencias.
- Se recombinan las series temporales correspondientes a cada frecuencia (usando un procedimiento vagamente descrito y que usa como pesos el valor absoluto de la FFT para dicha frecuencia).
III.
El proceso descrito en el bloque anterior transforma la serie temporal en otra serie temporal. Luego el proceso se puede iterar un determinado número de veces. Al final, el modelo tendrá un número de parámetros —en principio— igual al número de parámetros que contenga cada inception block por el número de veces que se concatenen estas funciones.
IV.
Eso es casi todo. Porque en el artículo se habla poco de cómo (y contra qué) se entrena eso. O cómo se usa para predecir: lo que se cuenta arriba es un método para ¿resumir la estructura de la serie temporal? Además, uno puede pensar: ¿qué pasa si la serie temporal es una recta creciente? No está nada claro cómo se pueden proyectar valores fuera del rango de valores observado si todo lo que se usa para modelar son fotos.
En el apéndice de detalles de implementación, además de decirnos la marca y modelo de la GPU que usan para ajustar los modelos en los casos prácticos que ilustra el artículo, los autores escriben:
All the baselines that we reproduced are implemented based on configurations of the original paper or official code. It is also notable that none of the previous methods are proposed for general time series analysis. For a fair comparison, we keep the input embedding and the final projection layer the same among different base models and only evaluate the capability of base models. Especially for the forecasting task, we use a MLP on temporal dimension to get the initialization of predicted future. Since we focus on the temporal variation modeling, we also adopt the Series Stationarization from Non-stationary Transformer (Liu et al., 2022a) to eliminate the affect the distribution shift.
De lo anterior se induce vagamente que:
- Para la predicción usan otra cosa, MLP (multi-layer perceptron), pero no dicen exactamente cómo. Supongo que uno puede bucear en el código de la cosa (disponible) pero no tengo paciencia.
- Reconocen que, bueno, a pesar de que los métodos tradicionales tienen aplicabilidad limitada porque las variaciones de las series temporales del mundo real son demasiado complejas como para predefinirlas, su modelo tampoco puede. Y que basta con que la serie temporal en cuestión no sea estacionaria para que se vean obligados a transformarla previamente. ¡Se les ha escapado un pequeño patrón para nada infrecuente en las series temporales del mundo real para el que tienen que aplicar medidas correctivas específicas!
V.
La ciencia de datos en el mundo contemporáneo es muy extraña y misteriosa. Tengo la sospecha de que en cincuenta o cien años, cuando se eche la vista atrás, los que nos reemplacen se darán cuenta de que el 99% de lo que se publicó al respecto alrededor de 2023 eran probaturas más o menos ingeniosas que parecían funcionar ya sea por casualidad o por alguna modalidad más o menos justificable de mala conducta científica. O puede ser que toda esta literatura no sea otra cosa que los comentarios de aquellos ciegos que palpaban un elefante y opinaban sobre lo que tenían delante; un elefante que era real, que estaba —en el sentido ontológico del teérmino—; pero cuya naturaleza —como para nosotros los principios por los que desvaríos como los que se describen en este artículo— se les escapaba.