CatastRo, un paquete de R para consultar la API del Catastro
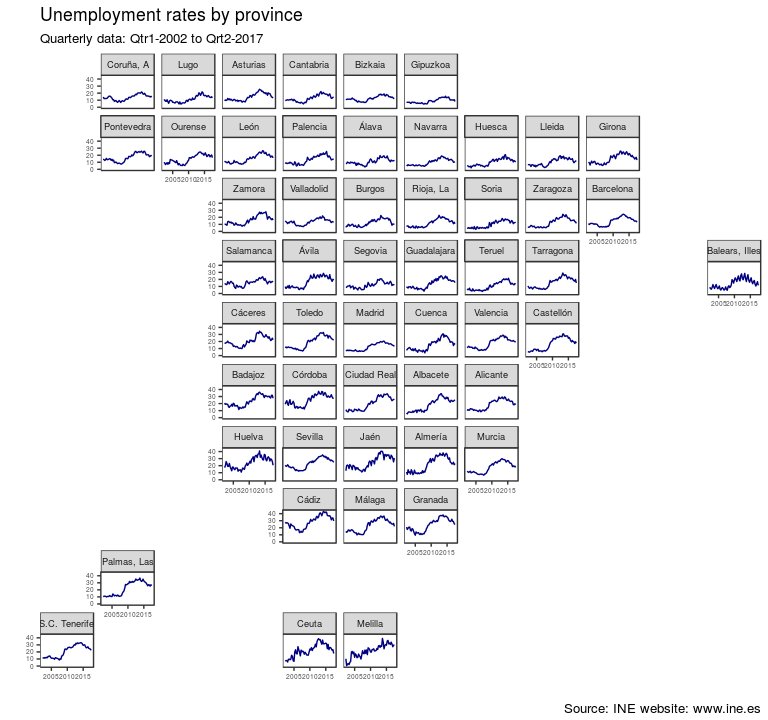
Informo de que está disponible en GitHub el paquete CatastRo para consultar la API pública del Catastro.
No es una API particularmente extensa, pero es de esperar que se amplíe el catálogo de servicios disponible cuando comencemos a machacarla (o no: a saber qué hay en la mente de esa gente).
El paquete es el trabajo de fin de máster de mi alumno Ángel Delgado Panadero en el máster de ciencia de datos de la UTAD.