Onodo: redes para contar historias
CartoDB (ahora Carto a secas) lo hizo con mapas. Onodo lo quiere hacer con grafos.
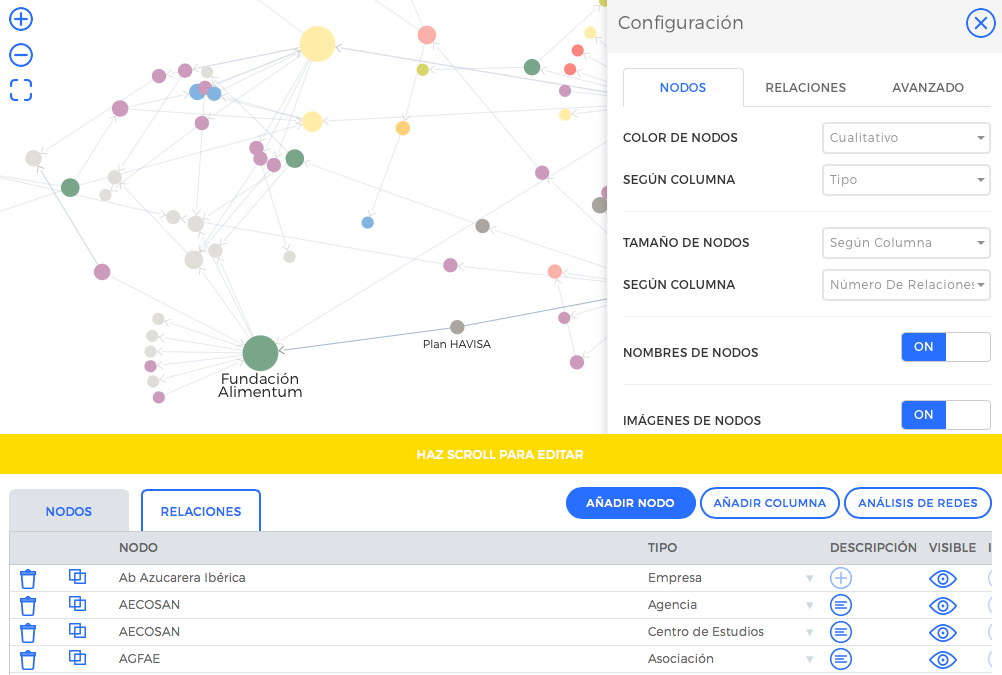
Onodo acaba de salir a la luz de mano de Civio y quiere convertirse en una herramienta para crear muy fácilmente visualizaciones interactivas de redes y nodos, y poder contar historias con ellas. Viene a ser un Gephi digamos que al alcance de (casi) todos, sin el aparataje matemático y orientado a la publicación en la web.