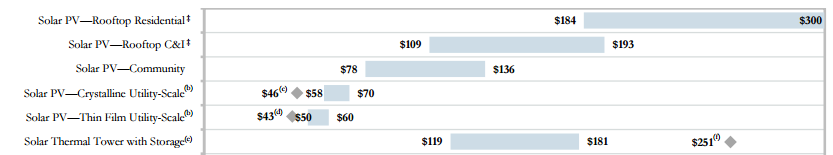Evidencialidad
Por afición y, últimamente, por motivos laborales también, me ha preocupado cómo se refleja la incertidumbre en el lenguaje y cómo este sirve para transmitir aquella (véase, por ejemplo, esto).
En el español tenemos algunos recursos para manifestar grados de certidumbre (el condicional, el subjuntivo, etc.). Véanse por ejemplo (esta es la referencia) a los 570 sufridos hablantes del tuyuca que no pueden decir simplemente “él jugaba al fútbol”, sino que tienen que elegir obligatoriamente entre los diferentes sufijos verbales que (además de indicar la persona y el tiempo) indican el modo por el cual el hablante obtuvo el conocimiento que afirma en el enunciado: