Cuestiones que no vienen al caso me empujaron finalmente a escribir una entrada que llevaba creo que años aparcada: ilustrar el uso del filtro de Kalman desde una perspectiva explícitamente bayesiana, luego accesible.
Introducción
Esto va, en resumidas cuentas, de mejorar la precisión de un sensor (un GPS, p.e.) que proporciona información ruidosa sobre la posición de un objeto que se mueve en el espacio obedeciendo ciertas ecuaciones. En particular, voy a utilizar el caso de un móvil que parte del origen ($x_0 = 0$), con una velocidad inicial de $10$ y que está sometido a una aceleración constante de $-0.3$.
Posición “real” del móvil
Para determinar la posición real del móvil podemos integrar las (¿consabidas?) ecuaciones del movimiento usando el método de Euler (que, como es sabido, no es el mejor y, por lo tanto, justifica el uso de la cursiva). Los parámetros del movimiento son
import numpy as np
import matplotlib.pyplot as plt
dt = 0.3
acc = -.2
F = np.array([[ 1, 0],
[dt, 1]])
G = np.array([0.5 * dt * dt, dt]) * acc
true_x0 = np.array([0, 10])y la integración (vía Euler) de dichas ecuaciones,
true_pos = [true_x0]
for i in range(int(100/dt)):
true_x0 = np.matmul(true_x0, F) + G
true_pos.append(true_x0)produce la siguiente trayectoria (real pero, en principio, desconocida):
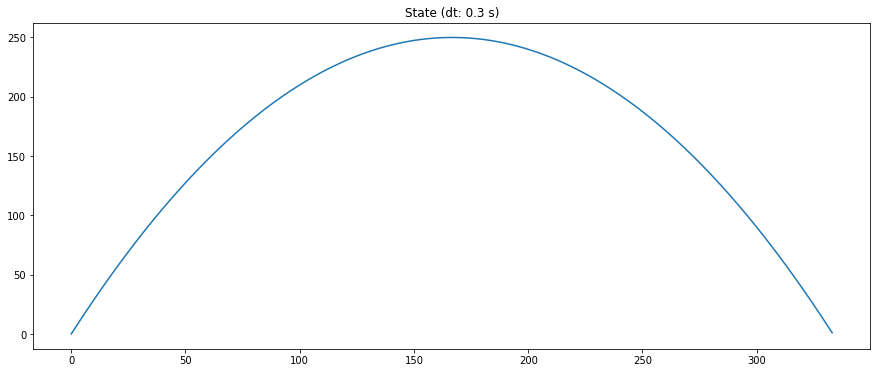
Los datos observados
A lo largo de la trayectoria del móvil, habremos ido observando aquello que nos indique el sensor, que es la posición real más un error (normal de varianza conocida):
obs_sd = 5
observed_pos = true_pos_pos + np.random.normal(0, obs_sd, len(true_pos_pos))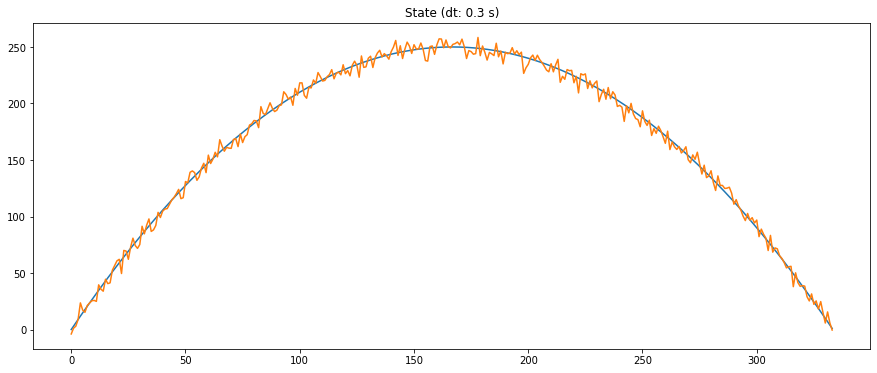
El objetivo de todo lo que sigue es mejorar esa posición en tiempo real aprovechando el conocimiento que se tiene de la dinámica del móvil (es decir, de las ecuaciones que rigen su movimiento, de la aceleración, etc.) y del error del sensor (es decir, su varianza).
El filtro de Kalman
Supongamos que el $t=0$ solo conocemos aproximadamente el estado (posición y velocidad) del móvil $x_0$ a través de una distribución de probabilidad $p$ (que, sin demasiada pérdida de generalidad supondremos normal en lo que sigue):
init_mu = np.array([0, 10])
init_sd = np.array([[1, 0], [0, 1]])
x0 = np.random.multivariate_normal(init_mu, init_sd, 10000)Podemos transicionar x0 aplicando las ecuaciones de evolución del sistema para ver cuál sería la distribución resultante, $p(x_1)$ después de dt segundos
x1 = np.matmul(x0, F) + Gpara obtener
![]()
Es decir, hemos pasado de una distribución (normal, por elección) a otra (que también es normal, por las propiedades de esa distribución y la particular forma, una transformación lineal, de las ecuaciones que rigen el movimiento). En este caso particular, podríamos explicitar la media y covarianza de la distribución resultante analíticamente, pero, ¿para qué?
Pero $p(x_1)$ es solo parte de la historia. Tenemos $o_1$, la posición leída del sensor, por lo que la distribución de interés no es tanto $p(x_1)$ sino
$$p(x_1 | o_1) \propto p(o_1|x) p(x)$$
El filtro de Kalman es un proceso iterativo que estima $p(x_n | o_n)$ para cada $n$.
Existen muchas maneras para muestrear la posteriori, $p(x_1 | o_1)$, y de entre todas ellas, en el código que sigue, me he decantado, por sencillez, por una de las peores, el ABC.
best_estimate_pos = [np.mean(x0[:,0])]
for i in range(int(100/dt)):
# dynamics
x1 = np.matmul(x0, F) + G
# prior parameters
x1_mean = np.mean(x1, axis = 0)
x1_cov = np.cov(x1.T)
# posterior sampling via ABC
n_abc_samples = 10000000
tmp = np.random.multivariate_normal(x1_mean, x1_cov, n_abc_samples)
dist = tmp[:,0] + np.random.normal(0, obs_sd, n) - observed_pos[i]
posterior_sample = tmp[np.abs(dist) < 0.01, :]
# posterior parameters
x0_mean = np.mean(posterior_sample, axis = 0)
x0_cov = np.cov(posterior_sample.T)
# best estimation is the mean of the posterior
# we know that in this case it is a normal distribution!
best_estimate_pos.append(x0_mean[0])
x0 = np.random.multivariate_normal(x0_mean, x0_cov, 10000)Finalmente, la trayectoria estimada vía Kalman,
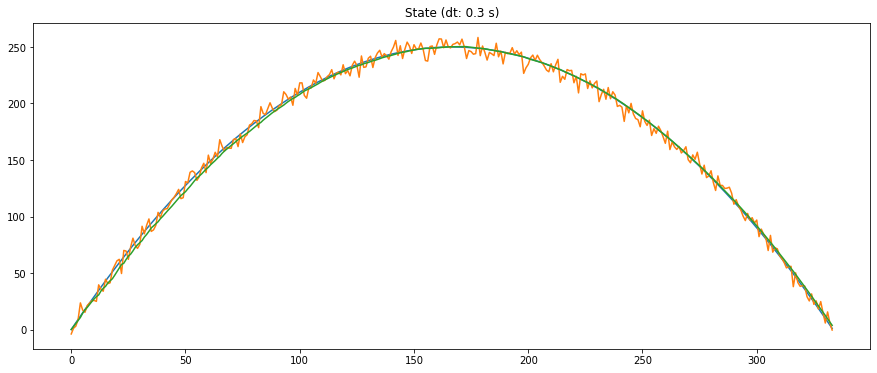
que, como puede apreciarse, está mucho más próxima a la verdad que las medidas, sustancialmente más ruidosas, del sensor.