Tenía ganas de meterle mano al modelo 3PL de la teoría de respuesta al ítem. Había un par de motivos para no hacerlo: que viene del mundo de la sicometría, que es un rollo macabeo, y que sirve —en primera aproximación— para evaluar evaluaciones (preguntas de examen, vamos), un asunto muy alejado de mis intereses. Pero acabaron pesando más:
- Que se trata de un modelo generativo en el que los coeficientes tienen una función —y por tanto, interpretación— determinada y prefijada. Es decir, un modelo ad hoc construido desde primeros principios y no usando herramientas genéricas —piénsese en las anovas o similares—.
- Que exige métodos de ajuste específicos. Por ahí usan MV vía EM.
- Que pide a gritos una aproximación bayesiana, sobre todo a la hora de prefijar la distribución de las habilidades de los alumnos.
- Que, finalmente, puede aplicarse fuera del estrecho ámbito de la teoría de la respuesta al ítem.
- Y, además, que es fácilmente generalizable.
El problema en el que el modelo 3PL se propone como solución es sencillo:
- $N$ alumnos toman un examen.
- El examen consiste en $n$ preguntas.
- Las preguntas son desiguales en términos de dificultad, etc.
El modelo 3PL postula que:
- Cada alumno tiene una habilidad $\theta_i$ que es la que el examen trata de evaluar. Se supone además, que estas habilidades tienen una distribución $N(0, 1)$ en la población general (de alumnos, no del mundo mundial).
- La probabilidad de que el alumno $i$ responda correctamente la pregunta $j$ es
$$p_j(\theta_i) = g_j + \frac{1 - g_j}{1 + \exp(-\delta_j(\theta_i - d_j))}$$
donde
- $g_j$ es la probabilidad de acertar la pregunta al azar,
- $\delta_j$ es la capacidad discriminativa de la pregunta (es decir, la capacidad para discriminar a los estudiantes según su habilidad) y
- $d_j$ es la dificultad intrínseca de la pregunta.
El modelo parece (y no solo en el nombre) una regresión logística de toda la vida, salvo por dos detalles: el parámetro $g_j$ y que las $\theta_i$ son desconocidas (y, de hecho, parámetros importantes que estimar).
Nótese además cómo $d_j$ y $\theta_i$ entran en la probabilidad anterior a través de su diferencia. Eso implica que, salvo que se especifique una priori para dichos parámetros, quedarán indeterminados en el modelo: nunca podríamos distinguir si el examen fue excesivamente complicado y los estudiantes habían estudiado mucho o si, por el contrario, el examen fue muy sencillo pero los estudiantes no lo habían preparado adecuadamente. Para anclar la diferencia hay que partir de las hipótesis de que la población de alumnos y la de preguntas procede de un universo en el que —por defecto— tienen distribución normal.
Este es uno de esos casos en el que las prioris del modelo tienen una interpretación objetiva: los estudiantes proceden de una población donde la habilidad tiene una distribución dada. Lo mismo podría predicarse de las prioris de los parámetros de las preguntas.
He ajustado un ejemplo (el que viene de serie en el paquete psychotools de R, MathExam14W) usando, por un lado la función nplmodel de dicho paquete —que usa MV— y, por el otro, numpyro, que interpreta bayesianamente el modelo. El código y los resultados de este último ajuste pueden consultarse aquí.
Por referencia, reproduzco aquí la parte más relevante del código, el modelo en sí:
def model3pl(scores, n_students, n_questions):
with numpyro.plate("students", n_students):
ability = numpyro.sample("ability", Normal(0, 1))
with numpyro.plate("questions", n_questions):
guessing = numpyro.sample("guessing", Beta(1, 1))
discrimination = numpyro.sample("discrimination", HalfNormal(1))
difficulty = numpyro.sample("difficulty", Normal(0, 1))
probs = ability[:, np.newaxis] - difficulty
probs = jnp.exp(-discrimination * probs)
probs = guessing + (1 - guessing) / (1 + probs)
probs = jnp.reshape(jnp.array(probs), (-1))
return numpyro.sample("scores", Bernoulli(probs), obs = scores)He usado como prioris la normal estándar para la habilidad y la dificultad, como se indica más arriba, una uniforme para la probabilidad de acertar al azar y una media normal poco informativa —más allá de fijarlo > 0— para el poder discriminante de la pregunta. La verdad, no se me ocurre cómo introducir a la versión frecuentista del problema toda esta información.
En cuanto a los resultados, la función psychotools::nplmodel da algo del estilo de
Three parameter logistic model
Slopes, intercepts and guessing parameters:
Estimate Logit Estim. Std. Error z value Pr(>|z|)
quad-a1 1.736e+00 NA 8.080e-01 2.149 0.031648 *
quad-d -1.696e+00 NA 1.058e+00 -1.602 0.109169
quad-g 3.750e-01 -5.109e-01 3.109e-01 -1.643 0.100323
deriv-a1 1.217e+00 NA 1.466e-01 8.299 < 2e-16 ***
deriv-d 1.138e+00 NA 1.134e-01 10.029 < 2e-16 ***
deriv-g 3.765e-06 -1.249e+01 2.742e+02 -0.046 0.963668
elasticity-a1 1.314e+00 NA 1.592e-01 8.253 < 2e-16 ***
elasticity-d 1.460e+00 NA 1.287e-01 11.349 < 2e-16 ***
elasticity-g 4.350e-06 -1.235e+01 2.772e+02 -0.045 0.964476
integral-a1 1.594e+00 NA 3.716e-01 4.290 1.79e-05 ***
integral-d -7.079e-01 NA 3.958e-01 -1.788 0.073722 .
integral-g 1.868e-01 -1.471e+00 4.582e-01 -3.210 0.001329 **
interest-a1 1.078e+00 NA 1.348e-01 8.000 1.24e-15 ***
interest-d 1.092e+00 NA 1.071e-01 10.194 < 2e-16 ***
interest-g 3.393e-06 -1.259e+01 2.772e+02 -0.045 0.963757
annuity-a1 1.265e+00 NA 1.471e-01 8.596 < 2e-16 ***
annuity-d 8.195e-01 NA 1.066e-01 7.690 1.47e-14 ***
annuity-g 5.837e-06 -1.205e+01 2.667e+02 -0.045 0.963955
payflow-a1 2.427e+01 NA 4.497e+01 0.540 0.589458
payflow-d -3.358e+01 NA 6.254e+01 -0.537 0.591334
payflow-g 1.006e-01 -2.191e+00 1.438e-01 -15.229 < 2e-16 ***
matrix-a1 1.747e+00 NA 1.970e-01 8.866 < 2e-16 ***
matrix-d 8.911e-01 NA 1.261e-01 7.067 1.58e-12 ***
matrix-g 1.667e-06 -1.330e+01 2.767e+02 -0.048 0.961645
planning-a1 3.233e+00 NA 1.165e+00 2.776 0.005510 **
planning-d -2.972e+00 NA 1.200e+00 -2.476 0.013275 *
planning-g 2.593e-01 -1.050e+00 1.864e-01 -5.631 1.79e-08 ***
equations-a1 2.646e+00 NA 7.587e-01 3.487 0.000488 ***
equations-d -1.892e+00 NA 6.843e-01 -2.765 0.005694 **
equations-g 1.800e-01 -1.516e+00 2.845e-01 -5.330 9.79e-08 ***
hesse-a1 1.824e+00 NA 2.234e-01 8.165 3.21e-16 ***
hesse-d 1.966e+00 NA 1.809e-01 10.870 < 2e-16 ***
hesse-g 1.745e-06 -1.326e+01 2.787e+02 -0.048 0.962062
implicit-a1 1.504e+00 NA 1.687e-01 8.913 < 2e-16 ***
implicit-d 7.963e-01 NA 1.143e-01 6.964 3.30e-12 ***
implicit-g 2.016e-06 -1.311e+01 2.752e+02 -0.048 0.961999
lagrange-a1 1.188e+00 NA 3.780e-01 3.142 0.001679 **
lagrange-d -1.101e+00 NA 5.543e-01 -1.986 0.047085 *
lagrange-g 1.699e-01 -1.586e+00 6.127e-01 -2.589 0.009618 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Log-likelihood: -5390 (df = 39)
Number of EM cycles: 500
M-step optimizer: BFGScon sus estrellitas de otra época y todo, mientras que el resumen gráfico de las posterioris del ajuste vía numpyro puede consultarse en el enlace anterior. Aviso de que la versión bayesiana transmite mucha menos sensación de certeza sobre el valor de los parámetros, cosa que daría para otra entrada. Por ejemplo, las posterioris de las probabilidades de acertar de chiripa tienen este aspecto:
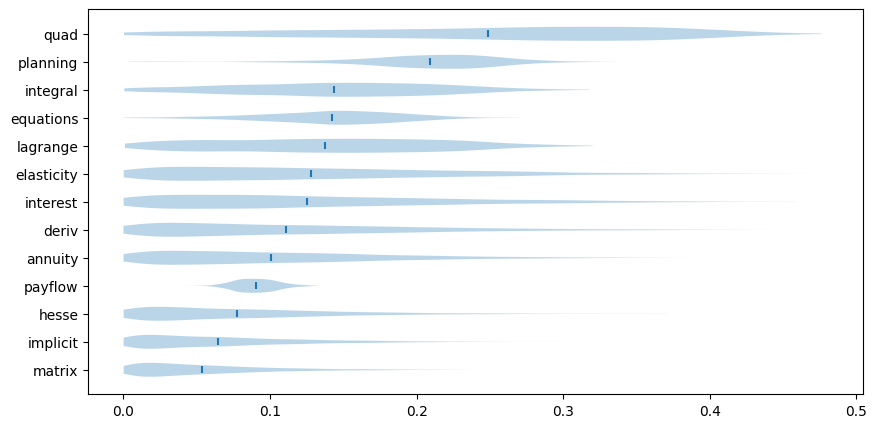
No he hecho, me ha faltado, un análisis de la correlación entre las distintas variables y, en particular, la existente —posiblemente bastante grande— entre la habilidad y la dificultad. Tal vez otro día.